
Recently, the topic of GenAI has been gaining a lot of traction. With the simple Jupyter notebook, we are able to train a model, create embeddings, integrate it with vector databases. But what next?
We should make the code to production where customers can access the model and try it out. We might have to push the notebook to github and then create a pipeline by using CI/ CD tools to deploy the model by using containerized platforms like Docker and Kubernetes. Instead of maintaining all these infrastructure, we can always use tools in the market which can automate the pipeline. One such tool is AirFlow.
We might have multiple steps in our code while the airflow makes sure that the steps are executed in correct order and pipeline is triggered at right time.
While we start coding we should architect our code in such a way that the task is divided into sequence of steps. For example, I would like to detect if a news is fake or not fake. What steps do you think we have?
- Fetch articles — get the list of articles from the API
- Preprocess text — Clean and normalize the text like removing stopwords and punctuations
- Vectorize text — convert this text into numerical format
- Predict — Use the pre trained ML model to classify if the article is fake or not fake.
- Store results — Save prediction to database
As you see the tasks are very clear and it is modularized. This is the prerequisite for the Apache Airflow and we would know the failure points easily across the pipeline and we can fix them.
Some important features with examples
Often, as a developer we might have this error where you have reached the API limits, atleast as a person who does not use premium products we face this issue or we are requesting for the tokens that are more than the API allows or may be network error which might require retrying. When my code is executed and stopped at this error, it still proceeds for next steps trying to find the data and performs operations on it which might result in nullpointer exception. The beauty of the Airflow is it allows us to retry and wait for the task to be completed before moving on the next step.
We can also process the tasks in parallel, for example, in the above scenario we might have to predict the news fake or not for 1000’s of articles. Instead of 1 by 1 we can process them in parallel.
Finally, we can set the pipeline to get triggered whenever there is new data available.
The Feature that I personally liked
Sometimes I experiment with multiple models and compare the performance of different ML models for which Jupyter notebook is quite handy. I can change the steps go back and forth, execute them. Once I finalize my code, I have to convert it to python file and then create requirements.txt with all the dependencies and then deploy it into the Production. But if I have go back and edit something, these steps are repeated. With Airflow, I no longer required to change the format to python.
- Pipeline automatically support code execution
- The code is modularized so it has good observability
- Robustness and notifications in case of failures
- We can use same python packages and tools
Each of my cell in the python notebook becomes the task of the pipeline and I can choose if my step should be retried if fails or should I proceed or should I give notification.
Terminologies to be aware of while using Airflow
- DAG — A data pipeline or part of data pipeline
- task — one unit of work in DAG
- UI — The airflow UI offering gives summary of current and past runs
DAG stands for Directed Acyclic Graph. It is a type of graph data structure where all the connections or “edges” have a direction, and there are no cycles, meaning you cannot follow a path of directed edges that leads back to the starting node.
Explore with Example
Suppose my aim is to develop a Book Recommendation System for which I might need a model that is trained with the books and its descriptions.
- Firstly, I take a pre-trained model and then use RAG framework and input it with the book and its descriptions.
- Next task will be to create embeddings of the books
- Finally, I will be storing it in vector database (local weaviate database).
Simple right. Let’s try coding this.
Import Libraries
import os
import json
from IPython.display import JSON
from fastembed import TextEmbedding
import weaviate
from weaviate.classes.data import DataObject
Set Variables
# Weaviate collection name
COLLECTION_NAME = "Books"
# Folder with books data
BOOK_DESCRIPTION_FOLDER = "include/data"
# Embedding model name
EMBEDDING_MODEL_NAME = "BAAI/bge-small-en-v1.5"
Create Local Instance of Weaviate
client = weaviate.connect_to_embedded(
persistence_data_path= "tmp/weaviate",
)
Create a Collection
existing_collections = client.collections.list_all()
existing_collection_names = existing_collections.keys()
if COLLECTION_NAME not in existing_collection_names:
print(f"Collection {COLLECTION_NAME} does not exist yet. Creating it...")
collection = client.collections.create(name=COLLECTION_NAME)
print(f"Collection {COLLECTION_NAME} created successfully.")
else:
print(f"Collection {COLLECTION_NAME} already exists. No action taken.")
collection = client.collections.get(COLLECTION_NAME)
Extract Text From Local Files
# list the book description files
book_description_files = [
f for f in os.listdir(BOOK_DESCRIPTION_FOLDER)
if f.endswith('.txt')
]
print(f"The following files with book descriptions were found: {book_description_files}")
Format the extracted data into Title, Author and Description
book_description_files = [
f for f in os.listdir(BOOK_DESCRIPTION_FOLDER)
if f.endswith('.txt')
]
list_of_book_data = []
for book_description_file in book_description_files:
with open(
os.path.join(BOOK_DESCRIPTION_FOLDER, book_description_file), "r"
) as f:
book_descriptions = f.readlines()
titles = [
book_description.split(":::")[1].strip()
for book_description in book_descriptions
]
authors = [
book_description.split(":::")[2].strip()
for book_description in book_descriptions
]
book_description_text = [
book_description.split(":::")[3].strip()
for book_description in book_descriptions
]
book_descriptions = [
{
"title": title,
"author": author,
"description": description,
}
for title, author, description in zip(
titles, authors, book_description_text
)
]
list_of_book_data.append(book_descriptions)
Create Vector Embeddings from description
embedding_model = TextEmbedding(EMBEDDING_MODEL_NAME)
list_of_description_embeddings = []
for book_data in list_of_book_data:
book_descriptions = [book["description"] for book in book_data]
description_embeddings = [
list(embedding_model.embed([desc]))[0] for desc in book_descriptions
]
list_of_description_embeddings.append(description_embeddings)
Load Embeddings to Weaviate
for book_data_list, emb_list in zip(list_of_book_data, list_of_description_embeddings):
items = []
for book_data, emb in zip(book_data_list, emb_list):
item = DataObject(
properties={
"title": book_data["title"],
"author": book_data["author"],
"description": book_data["description"],
},
vector=emb
)
items.append(item)
collection.data.insert_many(items)
Testing by Querying a book recommendation using Semantic Search
query_str = "A philosophical book"
embedding_model = TextEmbedding(EMBEDDING_MODEL_NAME)
collection = client.collections.get(COLLECTION_NAME)
query_emb = list(embedding_model.embed([query_str]))[0]
results = collection.query.near_vector(
near_vector=query_emb,
limit=1,
)
for result in results.objects:
print(f"You should read: {result.properties['title']} by {result.properties['author']}")
print("Description:")
print(result.properties["description"])
For Working Code — Visit Github
Running AirFlow in Local Docker
We have to set up Airflow in our local environment. We can install it and run as standalone application but preferred is docker as the docker compose file is available in the link.
This is pretty straight forward who are using docker already. There are detailed steps in the link
Once it is up and running on the localhost, you will see the status of each of the components in the airflow
AirFlow Architecture
I have put together a small picture of how Airflow architecture looks like with its functioning
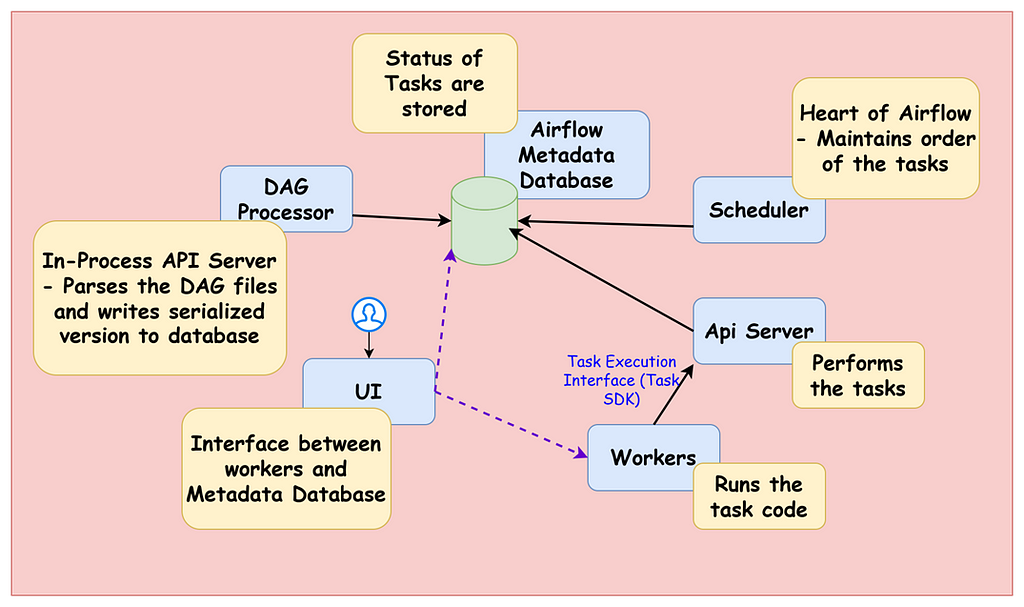
As we run this, we get the dags folder created automatically. This is the location where we can write the DAG files that is taken by the airflow automatically shows up on the UI.
Writing DAG for Book Recommendation System
AS we discussed, we would have 5tasks where we create collection, Extract book data, clean up the data into required format, create vector embeddings and store in the vector database. After this, we create a pipeline of it that ensures each task executed after the previous task using chain function.
The output of one task is input to the next task. Here is the simple DAG Flow:
from airflow.sdk import chain, dag, task
@dag
def fetch_data():
@task
def create_collection_if_not_exists() -> None:
pass
_create_collection_if_not_exists = create_collection_if_not_exists()
@task
def list_book_description_files() -> list:
return []
_list_book_description_files = list_book_description_files()
@task
def transform_book_description_files(book_description_files: list) -> list:
return []
_transform_book_description_files = transform_book_description_files(
book_description_files=_list_book_description_files
)
@task
def create_vector_embeddings(list_of_book_data: list) -> list:
return []
_create_vector_embeddings = create_vector_embeddings(
list_of_book_data=_transform_book_description_files
)
@task
def load_embeddings_to_vector_db(
list_of_book_data: list, list_of_description_embeddings: list
) -> None:
pass
_load_embeddings_to_vector_db = load_embeddings_to_vector_db(
list_of_book_data=_transform_book_description_files,
list_of_description_embeddings=_create_vector_embeddings,
)
chain(
_create_collection_if_not_exists,
_load_embeddings_to_vector_db
)
fetch_data()
Finally we query the database for the new data
from airflow.sdk import dag, task
@dag
def query_data():
@task
def search_vector_db_for_a_book(query_str: str) -> None:
pass
search_vector_db_for_a_book(query_str="A philosophical book")
query_data()
You can search for the DAG in the Airflow and click on the trigger

This is manual trigger. We can also schedule the pipeline.
we can add dag parameter with the cron schedule job
@dag(
start_date=datetime(2025, 4, 1),
schedule="@hourly"
)
There are also data-aware schedules which will be the trigger when the new data has been added to the embeddings. For this we use Asset event
@dag(
schedule=[Asset("my_book_vector_data")],
params={
"query_str":"A philosophical book"
}
)
Whenever there is update to weaviate embeddings it triggers this task
Now let us see how we can run the values of each task in parallel. It is simple it is by adding expand method
_create_vector_embeddings = create_vector_embeddings.expand(
book_data=_transform_book_description_files
)
This will create embeddings in parallel
Next important feature is adding retries automatically. Suppose we introduce divide by zero error which stops the other lines to execute
def fetch_data():
@task
def create_collection_if_not_exists() -> None:
print(10/0)
from airflow.providers.weaviate.hooks.weaviate import WeaviateHook
hook = WeaviateHook("my_weaviate_conn")
client = hook.get_conn()
For this we can add the arguments in the dag tag as follows
@dag(
start_date=datetime(2025, 4, 1),
schedule="@hourly",
default_args={
"retries": 1,
"retry_delay": duration(seconds=10)
}
)
This will help if the API is down, the automatic retries tries to fix this.
Congrats! we have successfully implemented production grade RAG framework.
