
Distributed Systems — Why is it important?
There was a time where the applications have one backend code that is responsible for all the functionalities that the application provide. One frontend code that tackles all the functionalities related to UI. All of this exist in a single server. But as the application complexity grows with the increasing number of consumers.
System design is an essential process in software engineering that involves designing a software system’s architecture, components, interfaces and data management strategies.
What is a Distributed Software System?
Distributed software system consists of multiple independent components, processes, or nodes that communicate and coordinate with each other to achieve a common goal. Unlike, centralized software system, where all the components are located on a single machine, a distributed software system is spread across multiple machines, networks and geographical locations.
Each component in a distributed system is responsible for a specific task or set of tasks and they work together to achieve a common goal. The components communicate with each other using a variety of communication protocols, such as remote procedure calls (RPCs), message passing or publish-subscribe mechanisms.
Distributed software systems are often used in large scale applications where scalability, availability and fault tolerance are critical requirements. Examples of distributed software systems include cloud computing platforms, peer-to-peer networks, distributed databases, and content delivery networks (CDNs)
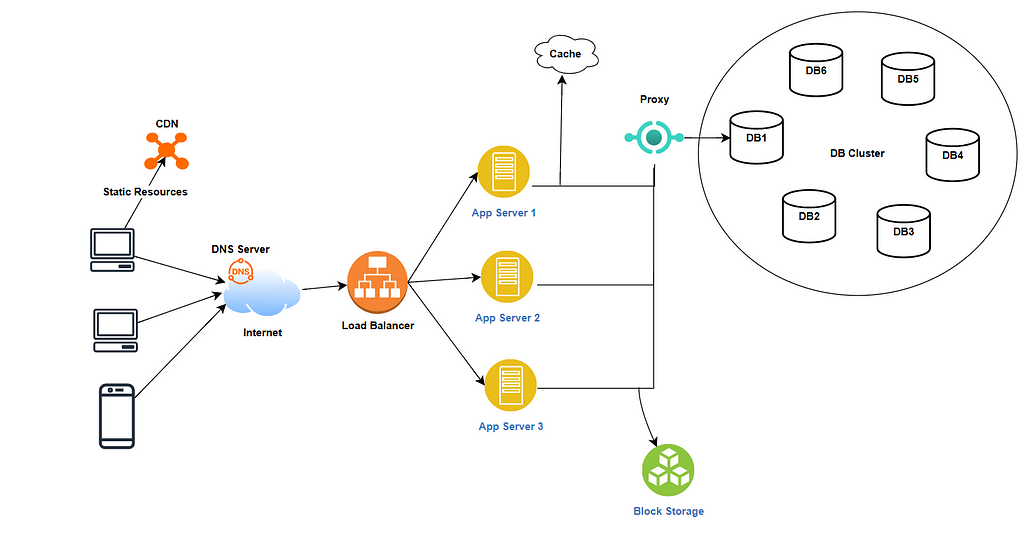
This is an example of distributed system with multiple computer resources and networks. There are user devices like laptop, mobile, tablets with which we submit requests and consumer information. These requests are routed to servers via the DNS server and load balancer to be processed. The server talks to different types of storage systems and databases to fetch the data needed to process and respond to the original request
The software system design process typically involves the following steps:
- Requirement Analysis — Understanding and defining the functional and non-functional requirements of the system. This step also calls for a deeper look into the read-and-write patterns and then designing the system to take advantage of these patterns.
- High level architecture design — Defining the overall structure of the system including its components, modules and interfaces
- Detailed Design — Defining the internal structure and behavior of each component and module. This also involves the core algorithms of each component and mechanisms of interactions between components.
- User Interface Design — Designing the user interface of the system that would interact with the backend services via APIs. This is to be done at a very high level
- API Design — Defining proper APIs, which would enable the user interface or the frontend to interact with the backend services.
- Database Design — Designing the data structures and storage mechanisms used by the system. The database could be simple file storage to a relational database such as My SQL or a NoSQL databases such as HBase or Cassandra
High Level System Design
The Key aspects of high level system design includes:
System Architecture
Crucial aspect of high level system design is defining the overall architecture, which outlines the main components, their relationships and communication patterns.
- Monolithic — A single, self-contained application that combines all system components
- Client -server — A distributed architecture where clients request services from one or more servers
- Microservices — A modular architecture with small, independent services that communicate over a network
- Event-driven — A system where components communicate through asynchronous events or messages.

This figure shows the high level system design architectural diagram.
The high level system design focuses on the clarity of system architectural choices and addresses the following features:
- Scalability — will the architecture support the system’s growth in terms of users, data and functionality?
- Maintainability — How easy will it be to update, debug or enhance the system?
- Reliability — Can the architecture ensure the system’s uptime, fault tolerance and resilience?
- Latency — How will the architecture affect the system’s response time and performance?
Data Flow
A well — designed data flow ensures that the system can ingest, process, store and retrieve data efficiently. When designing we consider the following —
- Data Ingestion — Identify the sources of data and the mechanisms for ingesting it into the system
- Data Storage — Determine the appropriate storage solutions for the data, considering factors such as access patterns, query performance and consistency requirements
- Data Processing — Design the processes that transform, analyze or aggregate the data, considering the necessary compute resources and potential bottlenecks
- Data Retrieval — Define how the processed data is accessed by clients or other components, considering latency, caching, and load balancing strategies
Scalability
It is the critical aspect of high-level system design as it determines the system’s ability to handle increased workloads without significant degradation in performance. There are 2 types of scalability
- Vertical Scalability — Improving performance by adding resources to a single component, such as increasing CPU, memory or storage
- Horizontal scalability — Improving performance by distributing the workload across multiple components or instances, such as adding more servers to a cluster
When designing for scalability, we must consider load balancing, caching, data partitioning and exploring stateless services.
Fault Tolerance
Fault Tolerance is the system’s ability to continue functioning despite failures or errors in its components. A fault tolerant system is more reliable and less prone to downtime. Some key strategies for designing fault-tolerant systems include replication, redundancy, graceful degradation, monitoring and self healing
Low-Level System Design
It focuses on the implementation details of the system’s components. This includes selecting appropriate algorithms, data structures and APIs to optimize performance, memory usage, and code maintainability.
Algorithms
Step by step procedures for performing calculations, data processing and problem solving in low-level system design. When selecting an algorithm, consider the following factors:
- Time Complexity — The relationship between input size and the number of operations the algorithm performs
- Space Complexity — The relationship between the input size and the amount of memory the algorithm consumes
- Trade-offs — The balance between time and space complexity, depending on the system’s requirements and constraints
Writing an optimized algorithm is a far better choice than leveraging high-end machines in any system.
Data Structures
Data Structures are used to organize and manage data in memory, impacting the system’s performance and resource usage. Choosing appropriate data structures is crucial for low level system design.
- Access Patterns — The frequency and nature of data access, including reads, writes and updates.
- Query performance — The time complexity of operations such as search, insertion and deletion
- Memory usage — The amount of memory required to store the data structure and its contents
Common data structures includes arrays, linked lists, hash tables, trees and graphs.
APIs
Application Programming Interface are essential for communication between different components or services in the system. They define the contracts that enable components to interact while maintaining modularity and separation of concerns.
- Consistency —Ensure that the API design is consistent across all components making it easy to understand and use
- Flexibility — Design the API to support future changes and extensions without breaking existing functionality
- Security — Implement authentication, authorization and input validation to protect the system from unauthorized access and data breaches
- Performance — Optimize the API for low latency and efficient resource usage
This enables to building backward-compatible systems
Code Optimization
This refers to techniques that improve code performance, readability and maintainability. In low level design code optimization is essential for ensuring that the system performs well under real-world conditions. Some techniques are
- Refactoring — Restructure the code to improve its readability and maintainability without changing its functionality
- Loop unrolling — Replace repetitive loop structures with a series of statements, reducing loop overhead and improving performance
- Memorization — Reduces time to recompute results by storing the results of previous calls
- Parallelism — Break down tasks into smaller, independent subtasks that can be executed concurrently, reducing overall processing time
low-level system design focuses on the implementation, interface and optimization of the system
Distributed systems have become an integral part of modern computing infrastructure. With the rise of cloud computing and the internet, distributed systems have become increasingly important for providing scalable and reliable services to users around the world.
