
AWS offers different kind of tools. To understand them better, I tried picturizing the services in the best possible way
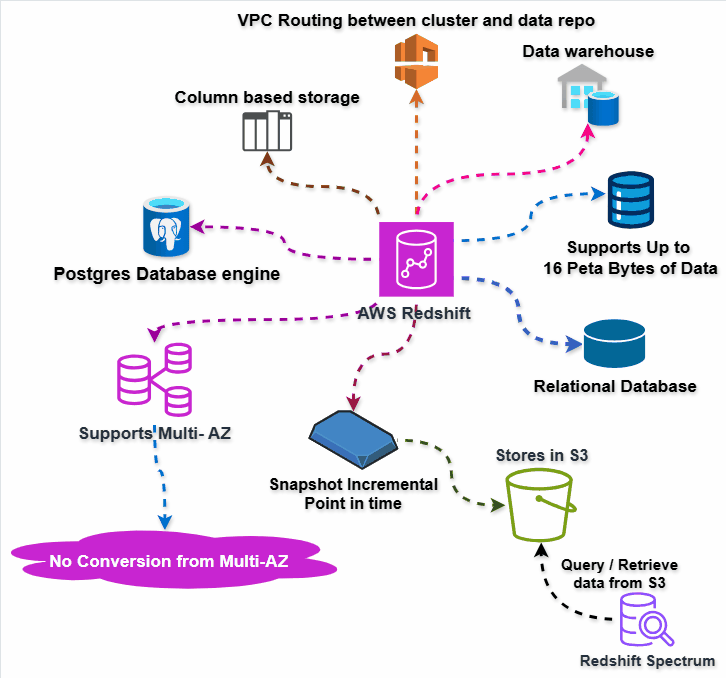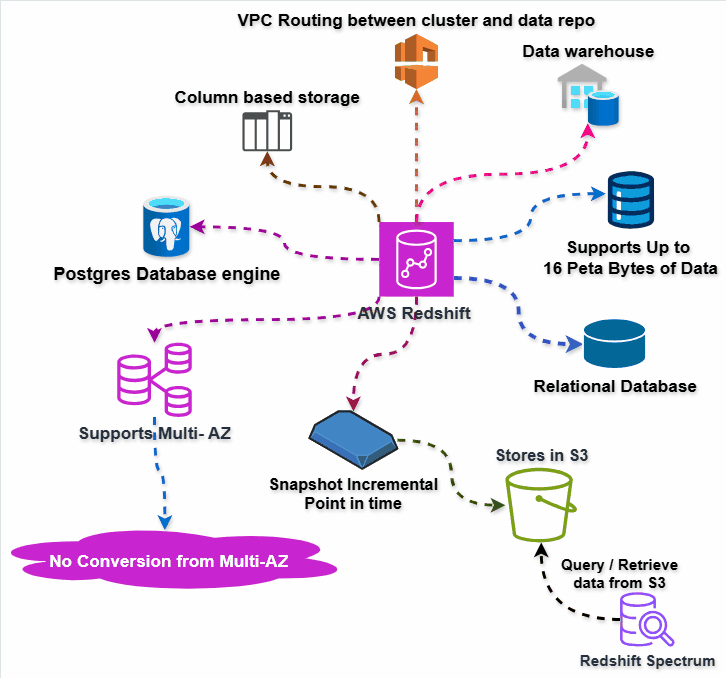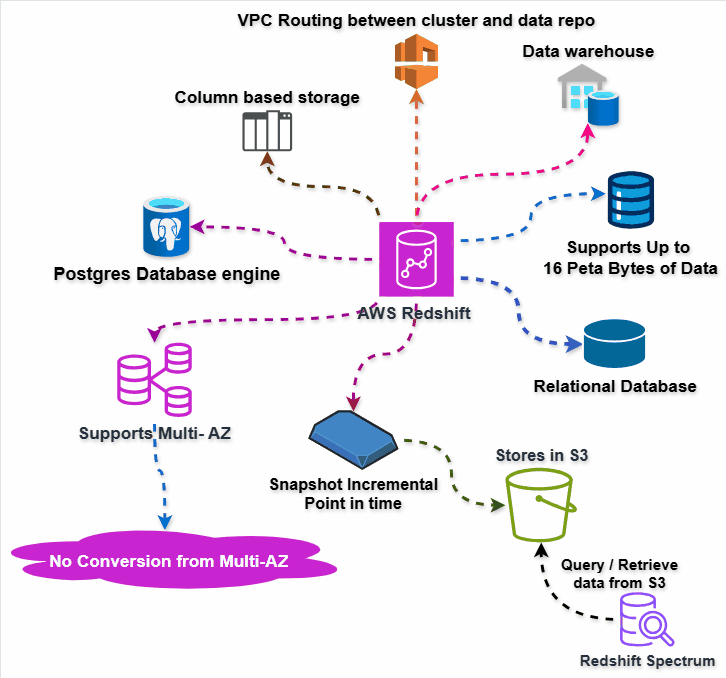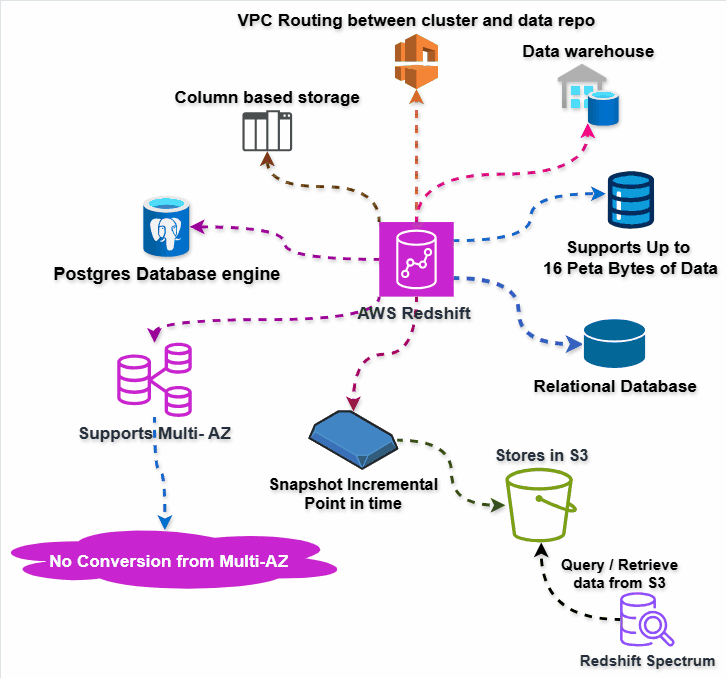
Amazon RedShift
Amazon Elastic MapReduce (EMR)
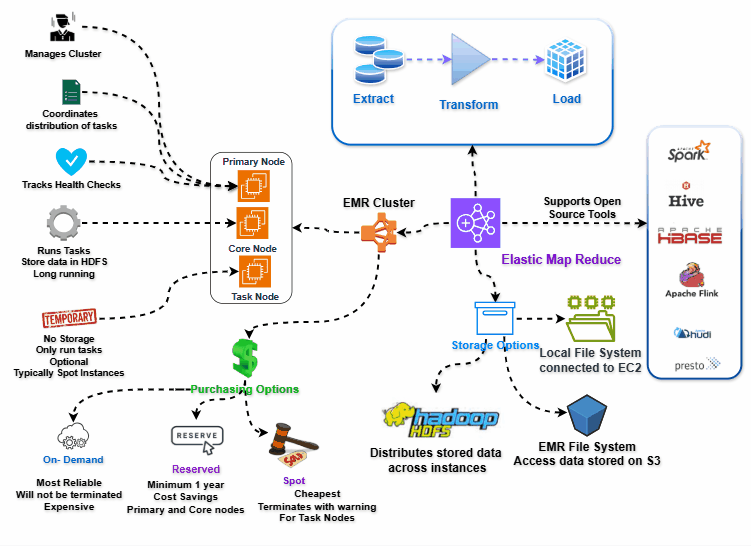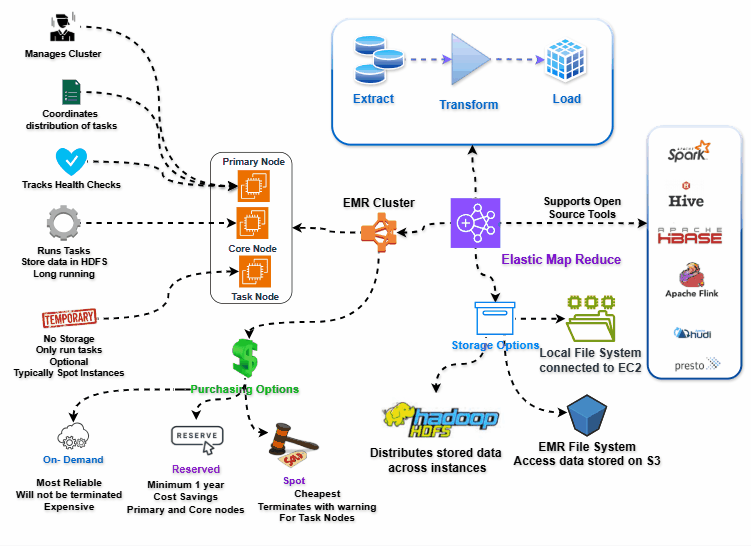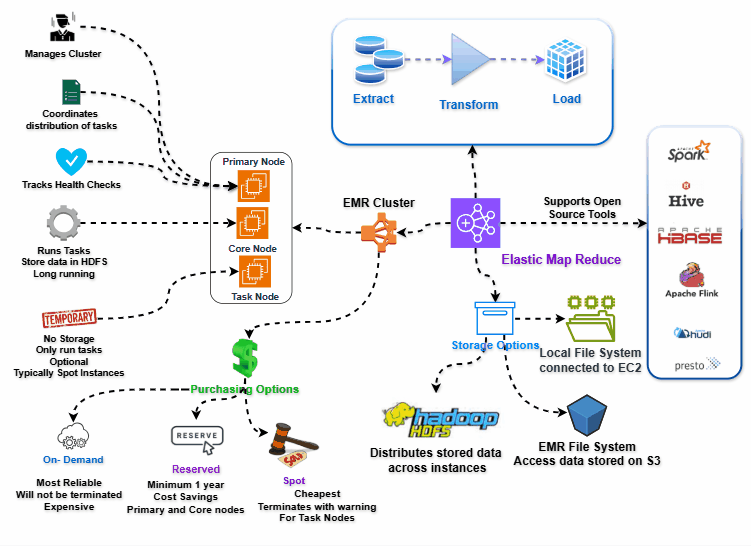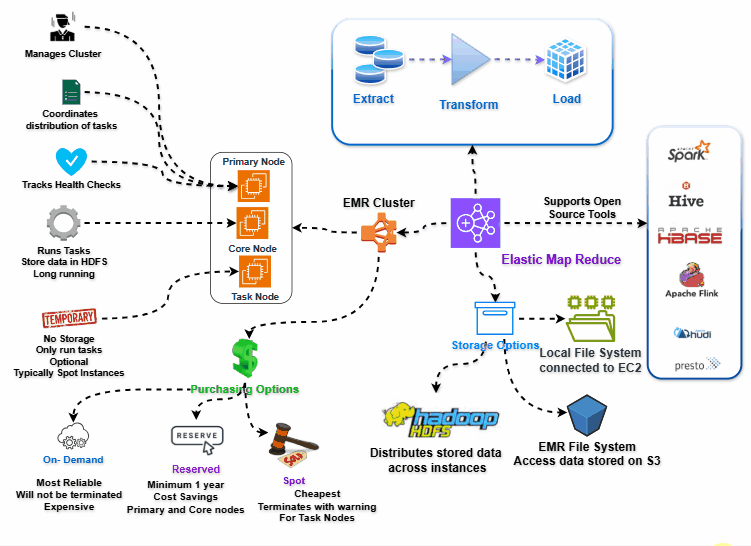
EMR Architecture
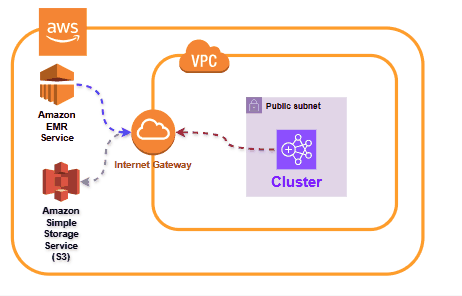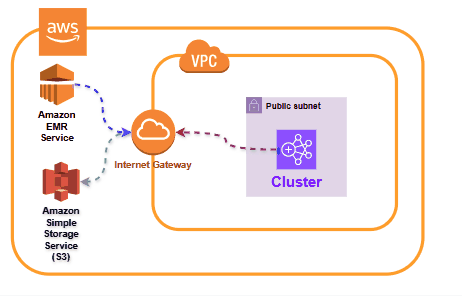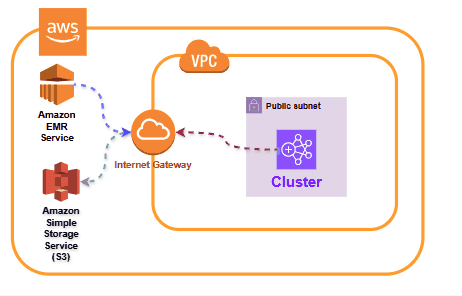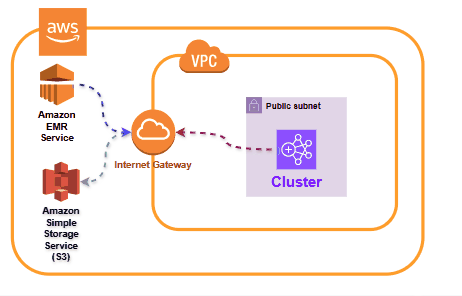
You can see our cluster in our VPC and our subnet, these clusters needs access to EMR service which means they need access to Internet or VPC endpoint access. Otherwise, EMR cannot manage cluster properly.
Same connectivity requirements goes to using S3 via EMRFS. But for this, Internet Access is costly and so we can leverage VPC endpoint for accessing S3 whenever possible.
Amazon Kinesis

SQS and Kinesis can both be queues. Each service has its pros and cons. SQS is easier and simpler where as Kinesis is faster and can store data for up to a year.
It is also real-time solution for processing or moving data
Amazon Athena and Amazon Glue
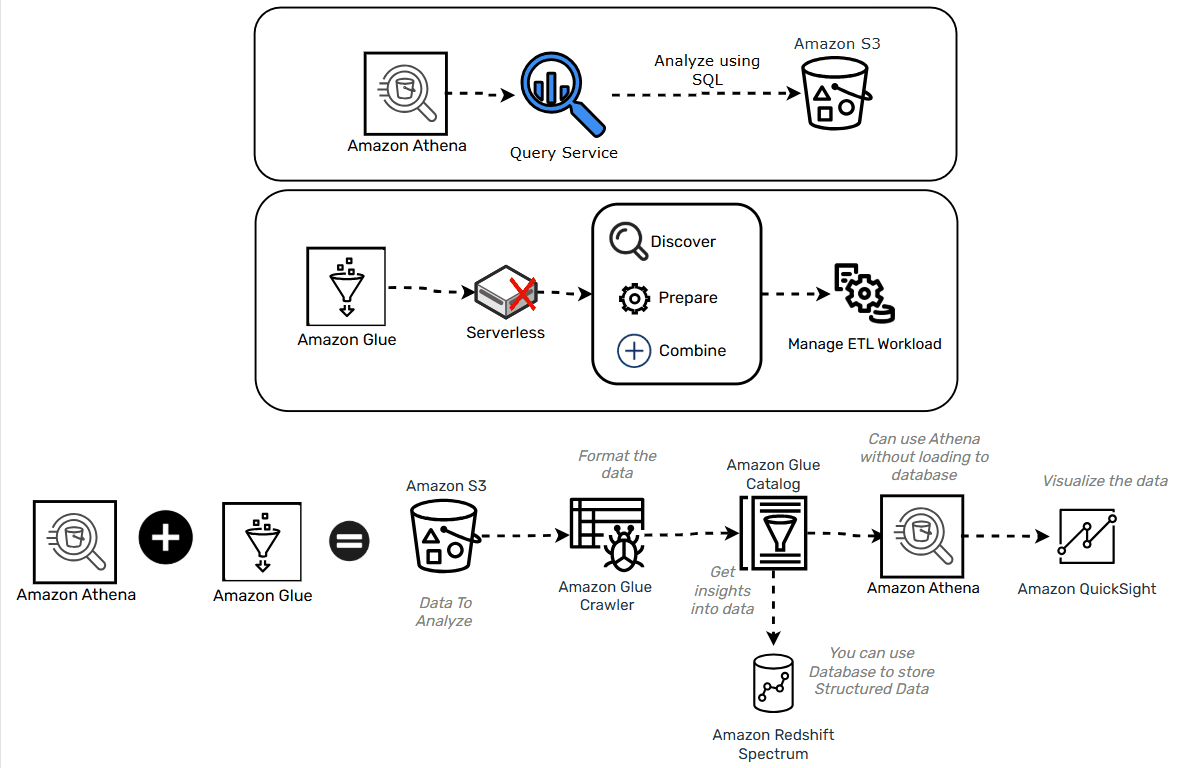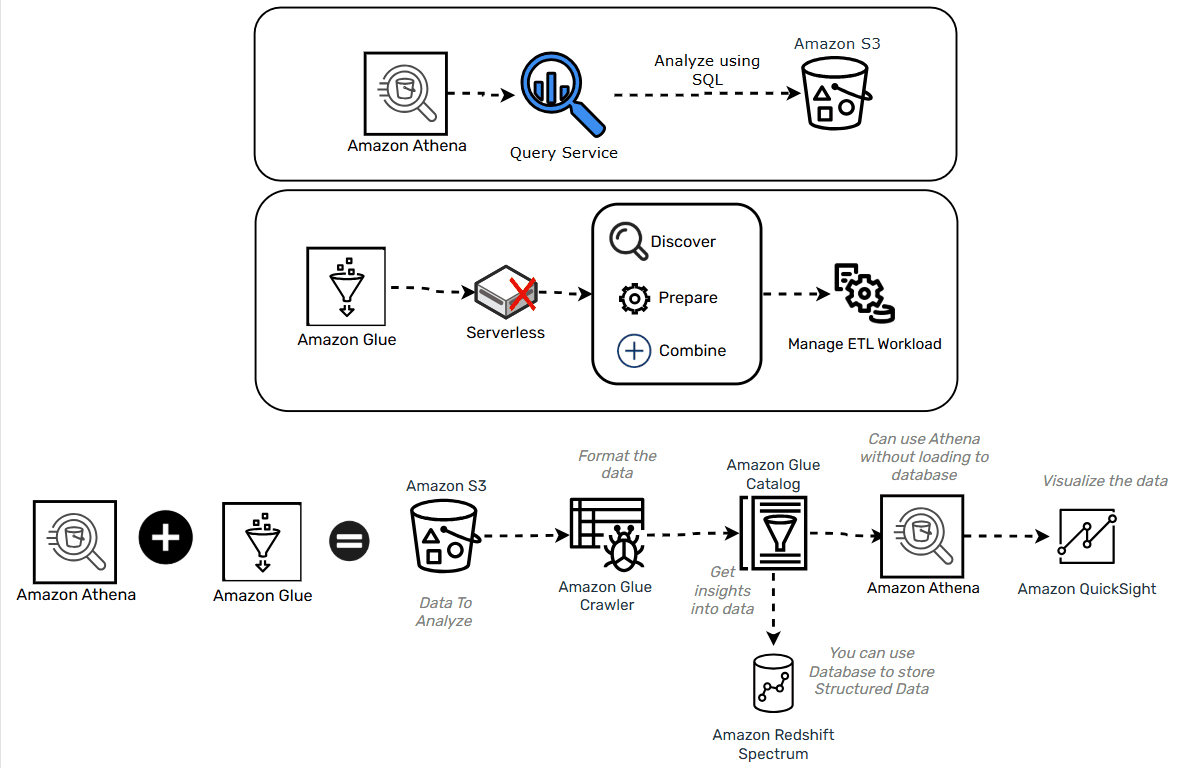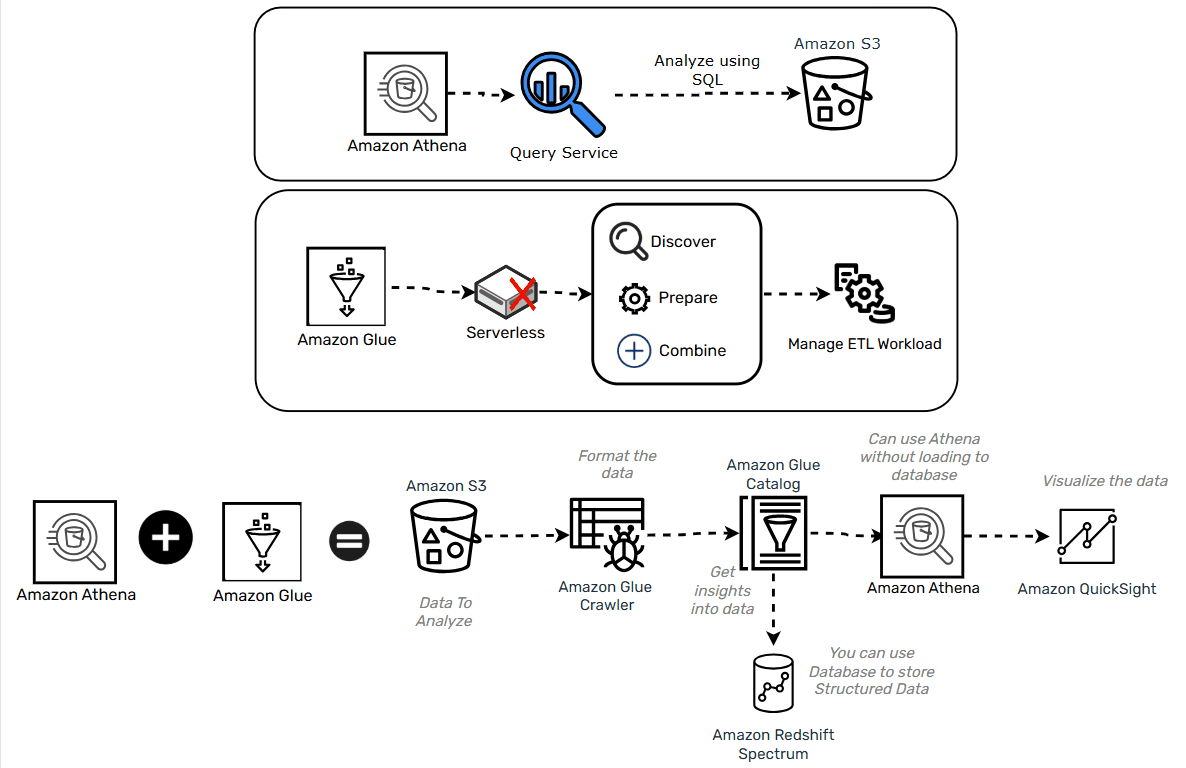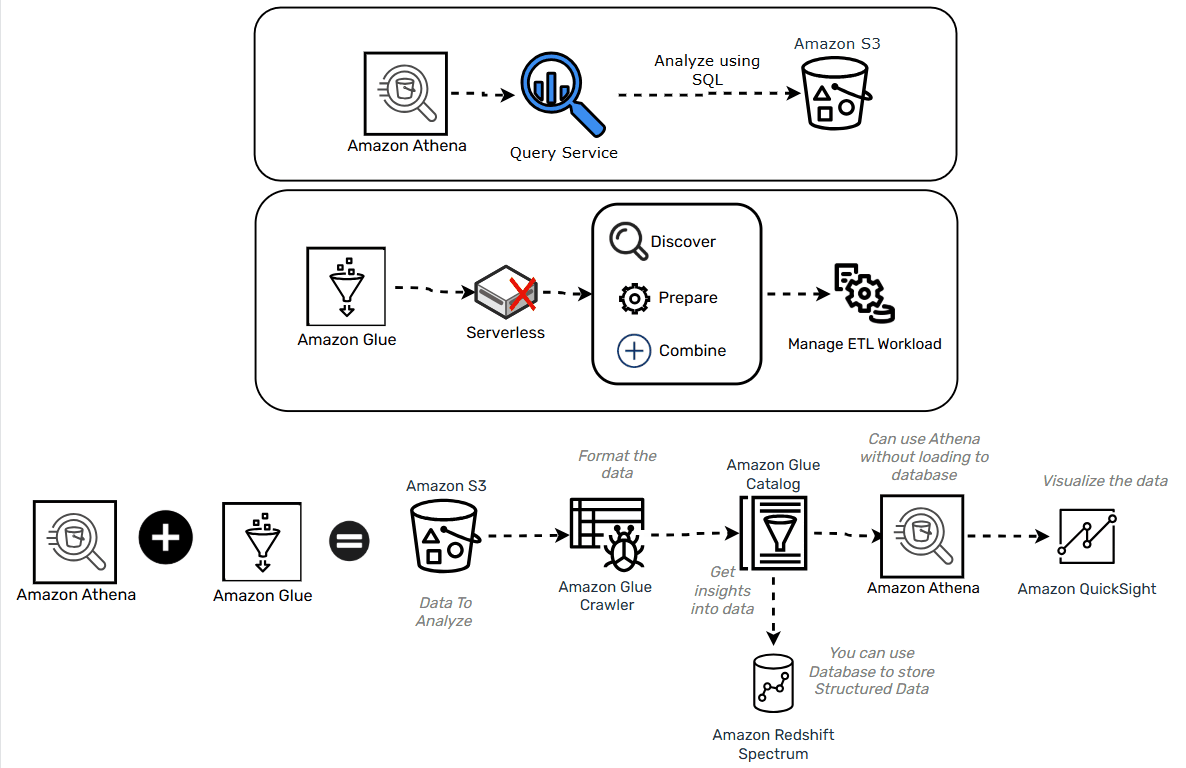
- Athena is serverless SQL querying service for the data stored in S3
- Glue is a serverless ETL service and can help create the schema for your data when paired with Athena
Amazon QuickSight

This tool is used for visualizing data
AWS Data Pipeline

- Data Driven — dependent on previous tasks completing successfully
- Parameters — enforces your chosen logic
- Highly available and distributed infrastructure.
- Automatically retries failed activities
- Integrates easily with Amazon DynamoDB, Amazon RDS, Amazon Redshift and Amazon S3
- Work with Amazon EC2 and Amazon EMR

Activities are the pipeline components that define the work to perform
Where can it be used?
- Processing data in EMR using Hadoop Streaming
- Importing or exporting DynamoDB data
- Copying CSV files or data between S3 buckets
- Exporting RDS data to S3
- Copying data to Redshift
Amazon Managed Streaming for Apache Kafka(Amazon MSK)

- It allows you to specify amount of Broker nodes per AZ at the time of cluster creation
- Zookeeper nodes are created for you
- Allows you to perform cluster operations with the console, AWS CLI or APIs within any SDK
- Kafka data-plane operations allow creation of topics and ability to produce/consume data

Some interesting features
- MSK Serverless — Full managed serverless cluster management. Automates the provisioning and scaling
- Full compatible with Apache Kafka — Serverless uses the same client apps for producing and consuming data
- MSK Connect — Allows developers to easily stream data to and from Apache Kafka clusters
Related to Security and Logging
- Integrates with Amazon KMS for SSE Requirements
- Encryption at rest by default
- TLS 1.2 for encryption in transit between brokers in clusters
- Deliver broker logs to Amazon CloudWatch, Amazon S3 and Amazon Kinesis Data Firehose
- Metrics are gathered and sent to CloudWatch
- All Amazon MSK API calls are logged to AWS CloudTrial
Amazon OpenSearch

It is primarily used for analyzing log files and various documents especially within an ETL process
Happy Learning!!
