
Is Google DeepMind — Mixture of Recursions replacing Transformers Architecture?
As we all know Transformers architecture introduced in 2017 played a key role in changing of the LLMs to be widely used across and has become the heart of the most famous GPTs, BERT models. Not only gained popularity but has became the turning point in the AI world. The same Google DeepMind who published the Transformers architecture recently in July 2025 has published a new architecture which is enhancement of the Transformers architecture with more smart abilities which is Mixture of Recursions.
Before we get into what Mixture of Recursions, for someone new to Transformers architecture, I would like to brief of what it is so you can understand what are the enhancements that are brought with this new architecture
Transformers architecture
This was the foundation of modern Large Language Models like GPT, BERT and others. It was introduced in the paper “Attention is all You need”. The main innovation is self- attention which allows the model to capture dependencies between words regardless of their distance in the input sequence.
The transformer architecture is composed of 2 main parts:
- Encoder — Reads and processes the input sequence ( for eg., Sentence)
- Decoder — Generates the output sequence step by step ( like translation, text generation)
In models like BERT which is the model used to classify text, understanding the semantic meaning, summarizing the text or answering questions from the context uses only Encoder part of the transformer architecture where as, the models like GPT, which generates text uses the Decoder architecture and for the models translating text from one language to other which requires ability to understand and generate the text has both the encoder and decoder architecture.
Internally the sentence passes through multiple layers

As you can see in the above picture, the input layer converts the words into embeddings and does positional encoding so the meaning is not changed. Then it is passed through self attention layer where attention is given to each word with respect to other words which is nothing but the relevance of each word to other Cat is relevant to Sat then it is given more weightage and less for other words. Similarly, this is done for each word in sentence in parallel. Once the output is generated, it is sent to feed forward network which is deep neural network- a mini fully connected network that interprets if the Cat is subject and how important is that word in the sentence. This loop is stacked and repeated 2–3 times and after multi passes we now know the semantic meaning what the sentence says.
This is how we classify the sentences or summarize text based on the importance in the sentence.
Let us now understand what decoder does.
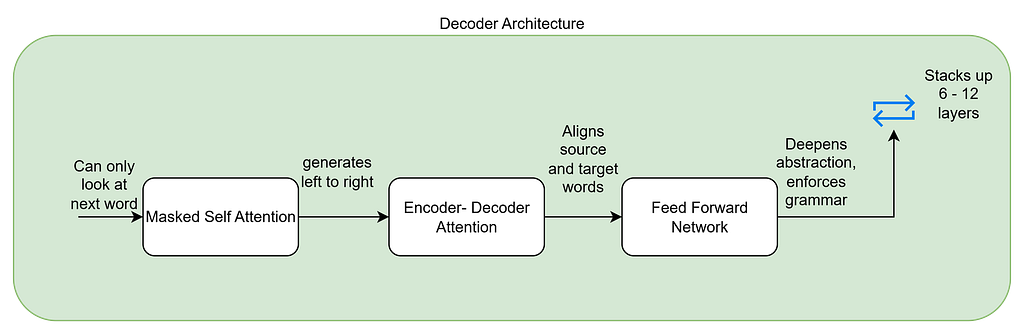
In the first layer, the decoder has only partial output. Masked attention means when predicting the next word, the decoder can only look at previous words and not the future ones. Suppose we have to translate the above example sentence to French, After start it generates “Le” not the translated word of cat. This enforces left to right generation and then the decoder attends each of the encoder’s output like the representations of “the Cat Sat on the mat” like cat has strong attention in the decoders query and so is the mat. This creates the alignment between source and target words. Once attention enriches each token, a position wise FFN transforms it through non-linear layers. This refines the word “chat” (translation of “cat”) and tags it to “noun, animal, subject of sentence”. this step increases abstraction and expressiveness. This is now passed through decoder layers 6 -12 times which finally gets better at each iteration with the grammar, verb conjugation and ensures sentence-level fluency.
The last decoder layer is not only translating the words but also generating fluent, grammatically correct, context-aware sentences.
This is the short and sweet understanding of Transformers architecture. Now that we are familiar with this let us take next step on Mixture of Recursions
Mixture Of Recursions(MoR)
The main goal of this paper is to reduce the computational cost and memory usage while keeping or improving model performance.
- The first modification they made to the existing transformers is that as you can see we are stacking many layers which increases the computation capacity. In this paper they shared something called fixed block of layers instead of having distinct layers. This helps parameter efficiency as we do not need to choose how many layers each time.

- Second modification is that as you see above the transformers architecture process each word with equal importance through all of the layers. In MoR, they changed it to token level adaptive recursive depth. For example, “The Cat sat on the mat” we are processing The equally as that of Cat. But in this model, we process Cat more times than the and drops “the” word early and it does not have so many recursions
- The third modification is as we are giving attention to each of the word and storing the scores of each of them it can blow up the memory. They have 2 KV strategies Recursive wise KV caching which stores only the active tokens that are going through recursion and the ones dropped is not stored. Recursive KV sharing reuses some KV pairs from the first recursion for subsequent ones to reduce latency and memory+
- They introduced router which takes decisions of each word on how many times it has to go through recursion. These are light-weight and are trained to assign token-specific recursion depths to decide how many times the shared parameter block is applied to each token. This reduces computation. They have 2 routing strategies which is Expert-choice routing which at each step decides which tokens continue deeper and Token-choice routing that decides for each token up-front how deep it will go.
Let us take the example we have seen so far, we have to tokens “The”, “cat” “sat”, “on”, “the”, “mat”. Suppose we have transformer architecture model has 6 distinct layers or in a recursive variant a shared block repeated 3 times uniformly across all the tokens. Every token goes through all layers or all recursions ( self attention + FFN in layer 1 and then recursion 2 and so on). All Key Value caches built for all tokens and all layers, the computation cost increases for every token.
Let us transform it to MoR architecture,
- Router decides the token complexity. May be “the” (article) is considered easy and need fewer recursions and “cat” (subject, noun) somewhat more complex, “sat” (verb) more complex, “on the mat” (prepositional phrase) maybe medium complexity
- Shared block of layers is applied recursively below the maximum recursion depth allowed let’s say 3. For each token, the number of recursions is between 1 and 3 as decided by router
“The” — 1 recursion, “cat” — 2 recursions, “sat” — 3 recursions, “on” — 2 recursions, “the” — 1 recursion and “mat” — 2 recursions
- During computation, all tokens pass through in the first recursion and from 2nd those tokens with the depth ≥ 2 is allowed through block again and remaining tokens exit.
- For attention operations, only active tokens are considered deeper and KV pairs exited earlier need not be computed or stored in later recursions. If using recursive KV sharing, maybe some KV pairs from earlier recursions are reused for later ones.
- For the result, “sat” being the most important in meaning or grammar gets more processing
The results tested models from ~135 million to 1.7 billion parameters. Under same FLOPs / compute budgets, MoR models outperform vanilla and recursive baselines in validation loss, few-shot accuracy, and throughput.
Limitations
- The router learns which tokens are important but might also makes mistakes in choosing the tokens that might benefit from more recursions can be exited early. There is a tradeoff
- Overhead of routing decision and bookkeeping (KV cache management) adds complexity
- The model in experiments is up to ~1.7B parameters so it remains to be seen how much the gains extend to very large models
- Structurally the nature of attention and feed-forward all remains same like the transformers architecture but only change is how many times the tokens has to go through the recursion.
