
Knowledge graphs is a powerful concept where we can represent any flow or entity relationships in a structured way.
Before diving into the knowledge graphs, let us first understand what is graph structure. We might have learnt about this in our school where we have a graph sheet with grids on it and plot the points like X,Y where horizontal line is X axis and vertical line is Y axis. If we have to plot a point (X, Y) then move X distance from the center and Y distance up/down from the center. If we have to draw a triangle, we have 3 vertices and plot them on the graph, and join them which becomes sides.
Similarly, if we join the points on graph with direction just like our map where we can move from one place to other and mention the direction. In graphs, the points are called nodes and the connecting lines are called edges. If the nodes has some meaning, which means in above case some location on the map, then it is knowledge graph. we can also represent social networks with friends and friends of friends or computer networks.
Regular graphs focus on structure and connections and have simple relationship types with limited semantic meaning where as knowledge graphs has rich semantic relationships between entities and has properties and attributes for nodes and edges with multiple types of relationships and has domain-specific information modeling.
We have directed graphs where there is explicit start and end node and undirected graphs which are connecting nodes. Once a graph is defined, various metrics can be extracted, such as centrality, community detection and path analysis. Centrality highlights the most influential nodes in a network community detection identifies clusters or groups of closely connected nodes and path analysis uncovers relationships and the shortest routes between nodes.
Representing Knowledge graphs —
- We can use adjacency matrix where each element in the matrix represents an edge between two nodes. If there is an edge between node i and node j, the matrix entry at [i][j] will have a non-zero value (usually 1) and if there is no edge the entry will be 0
- We can also use Adjacency list which is more space effecient way of representing graphs. Instead of using a 2D matrix, you store a list (dictionary in python) of neighbors for each node. This representation is more efficient in terms of memory usage especially for sparse graphs.
Saving Knowledge graphs in Python —
Knowledge graphs can be saved in many formats. Primary formats include
- NetworkX : In-memory representation, easy to work with for small and medium sized graphs.It can be used for running algorithms, testing ideas or visualizing smaller graphs during prototyping
- RDF ( Resource Description Framework): Graph represented as triples: (Subject, Predicate, Object). Used for Sematic Representation where graph is converted to RDF format and can be shared with others
- Neo4j: Graph Database for large scale, property rich graphs. Scalable solution to store graphs and can be used where fast retrieval is critical.
- SQL: Graphs stored as tables. Nodes stored as rows and edges stored in a separate table with foreign keys. Can be used when graph needs to seamlessly integrate with the relational databases but be aware of performance trade-offs
Property Graph Model
It is most popular model for modern graph databases.
- Nodes represents entities in the domain —
Can contain zero or more properties which are key-value pairs representing entity data such as price or date of birth.
Can contain zero or more labels which declare the node’s purpose in the graph such as representing a Customer or Product
- Relationships representing how entities interrelate
These relationships have a type like BOUGHT, FOLLOWS or LIKES and it has direction from one node to another. Also, it contains zero or more properties as key-value pairs representing some characteristic of the link like timestamp or distance and they never dangle.
These model does not enforce any schemas based on labels or relationship types. We can also apply constraints to be label to ensure those properties exist, are unique. In this model, there is no limits on number of nodes or number or type of relationships that interconnect them.
Knowledge graphs are graphs with emphasis on contextual understanding.
Organizing Principles of Knowledge Graph
There are different ways that data in knowledge graph be organized.
Plain Old Graphs
Representing the data is straight forward and the graphs can be interpreted only if the domain knowledge is present. The organizing principle is hidden in the logic of the queries and programs that consume the data in the graph.
Richer Graph Models
This is far more organized than plain old graphs. It supports labeled nodes, type and direction for relationships and properties on both nodes and relationships. This organizing principle makes a graph self-describing and is a clear first step toward making data smarter. By using node labels, the software can extract all similar types of entities from a graph. Also, some processing can be done without knowledge of the domain just by using the features of the property graph model.
It provides contract between the graph and its users. Consuming software can expect to find labeled nodes and directed, labeled relationships in the data. The property graph model is a contract, and software tools that uphold this contract can process, visualize, transform, and transmit the data in a manner that is consistent with its intent.
Using Taxonomies for Hierarchy
Labels do not tell us that one category is broader than another one or that certain products are compatible with others or are even possible substitutions based on the categories to which they belong. To support “x kind of y” reasoning, we need more hierarchial view of the data known as taxonomy. It organizes categories in a broader-narrower or generalization-specialization hierarchy. Items that share similar qualities are grouped into the same category, and the taxonomy organization places more specific things like products at the bottom of the hierarchy while more general things like product families are places toward the top of hierarchy. we can choose to compose multiple organizational hierarchies simultaneously to provide even more insight
Using Ontalogies for Multilevel Relationships
Like taxonomies, ontologies are classification schemes that describe the categories in a domain and relationships between them. Ontologies enable you to define more complex types of relationships between categories, such as PART_OF, COMPATIBLE_WITH, or DEPENDS_ON. They also allow you to define hierarchies of relationships and to characterize those relationships in more nuanced ways (transitive, symmetric, and so on). These concepts also map comfortably onto the labeled property graph model.

Ontologies make knowledge actionable, enabling human or software agents to carry out sophisticated tasks.
From these organizing principles, we can also build one to our need. While building this, one might consider natural language to describe the semantics or RDF schema. It seems that a mix of standards and adaptive customization is most aligned with the reality of modern business
Graph Databases
The most popular graph database in terms of its maturity and reach is Neo4j. The majority of the interactions with the database will be Cypher Query Language. It is declarative, pattern-matching query language.

Consider this graph where a node represents a person named Rosa and lives in node which is place called Berlin. We can represent this in query as (:Person {name: 'Rosa'})-[:LIVES_IN]->(:Place {city:'Berlin', country: 'DE'}).The :Person and :Place represents labels on those nodes -[:LIVES_IN]-> is the relationship between places and people. The {name:'Rosa'} and {city:'Berlin', country:'DE'} are key-value properties that can be stored on nodes
We can use create word to create this subgraph
CREATE (:Person {name:'Rosa'})-[:LIVES_IN {since:2020}]->
(:Place {city:'Berlin', country:'DE'})Labels group nodes together by role. When a node is created with a label, it is added to the index for that label. Most of the time, you will not notice the indexes but the database query planner uses them to make queries faster.
When storing data, direction of a relationship is mandatory since it creates a correct, high-fidelity model. Once data is loaded we can use Pattern matching which is using MATCH keyword

Importantly, you can traverse a relationship in either direction at the same constant cost. This is a fundamental tenet of the labeled property graph model.
Sometimes we may create duplicates so Cypher also supports DELETE which removes the matching records or cleanly aborts if that would leave any relationship dangling.
MATCH (n) DELETE n // Deletes nodes
// Cleanly aborts if it leaves relationships dangling.
MATCH ()-[r:LIVES_IN]->() // Deletes LIVES_IN relationships between any nodes
DELETE r
MATCH (n) DETACH DELETE n // Deletes all nodes and any relationships attached,
// effectively deleting whole graph.
MERGE is subtle. Its semantics are a mix of MATCH and CREATE insofar as it will either match whole patterns or create new records that match the pattern in its entirety.
We can also create the constraints like CREATE CONSTRAINT no_duplicate_cities FOR (p:Place) REQUIRE (p.country, p.city) IS NODE KEY. This statement declares that Place nodes need a unique composite key composed from a combination of city and country properties.In turn, this ensures the coexistence of London, UK, and London, Ontario, in the database but prevents duplicates of them (and any other city and country combination).
MERGE (london:Place {city:'London', country:'UK'}) // Creates or matches a node to
// represent London, UK
// Binds it to variable "london"
MERGE (fred:Person {name:'Fred'}) // Creates or matches a node to represent Fred
// Binds it to variable "fred"
MERGE (fred)-[:LIVES_IN]->(london) // Create or match a LIVES_IN relationship
// between the fred and london nodes
MERGE (karl:Person {name:'Karl'}) // Creates or matches a node to represent Karl
// Binds it to variable "karl"
MERGE (karl)-[:LIVES_IN]->(london) // Create or match a LIVES_IN relationship
// between the karl and london nodesThe graph will show

Correctly finding friends and friends of friends of someone who lives in Berlin
MATCH (:Place {city:'Berlin'})<-[:LIVES_IN]-(p:Person)<-[:FRIEND*1..2]-(f:Person)
WHERE f <> p
RETURN fIf the queries are specific to node like asking about Rosa or Berlin the graphs are called graph local queries. If the question is more generic like Which is the most popular cities to live in then it is called graph global.

Neo4j also supports calling functions and procedures which implement specific tasks. We can use CALL syntax

This CALL reveals the schema of the underlying knowledge graph
Another commonly used set of procedure calls comes from the APOC library. APOC is a popular library that ships with Neo4j and contains a plethora of useful functionality and shortcuts for operating on knowledge graphs.
the apoc.atomic.concat procedure atomically joins property strings together (with no partial results visible).
MATCH (p:Person {name:'Fred'})
// Fred becomes Freddy
CALL apoc.atomic.concat(p,"name",'dy')
YIELD oldValue, newValue
RETURN oldValue, newValue;Invoking functions is similar to invoking procedures, but you don’t need the CALL syntax. Instead, simply insert the function where you’d normally insert a value
RETURN apoc.date.convert(datetime().epochSeconds, "seconds", "days") as outputInDays;
There are two more tools you should know to become competent at Cypher. The EXPLAIN and PROFILE keywords help developers understand the performance of their queries, which is especially important as your knowledge graphs become larger. EXPLAIN provides a visualization of a query plan, guiding the developer toward reducing the amount of data (“DB hits”) flowing through the query. PROFILE goes one step further and instruments a running query to see the actual behavior at runtime
Neo4j Internals
It performs 2 major operations- Queries graph data performantly and Stores graph data safely
To perform the query, the database has to traverse from one node to another. For this, the Neo4j stores the structure of a graph( nodes and relationships) separately from the property data.
The graph structure is stored as fixed-length records: one for nodes and other for relationships. Multiplying the ID of a record by its size in bytes gives offset in corresponding store file. This pattern is known as index-free adjacency.
Index-free adjacency is such a powerful property because it gives you O(1) or “constant time” traversals. This means that graph query latency is proportional to the amount of graph traversed, rather than being proportional to the size of the graph.
Unlike node or relationship stores, property stores are O(N) or “linear time” for reads, meaning that access to a property is proportional to the number of properties stored for that node or relationship. For writes, the property stores remain O(1) since the new property is added to the head of the relationship chain.
Where possible, queries should traverse the graph structure first and then retrieve property data once target nodes and relationships have been found. This ensures that most work is done quickly and cheaply with O(1) operations, with fewer more expensive O(N) operations.
Neo4j maintains ACID (atomicity, consistency, isolation, durabil‐ ity) transactions across servers as well as in the single-server case. To do so, it uses an algorithm called Raft that keeps individual transaction logs “tied” together (hence the name). Atop Raft, Neo4j provides a causal barrier, which means that users of the database always see at least their own writes, even with servers spread out over a wide-area network. This causal feature is opt-in and transparent but makes working with the database cluster as simple as reasoning about a variable in a programming language.
Loading Knowledge graph data
The Neo4j Data Importer is a visual tool that allows you to draw your domain model as a graph and then overlay data onto that graph, with comma-separated values (CSV) files that contain the data for your nodes and relationships.
UNWIND is a Cypher clause that takes a list of values and transforms them into rows that are fed into subsequent statements. It’s a very common way to handle input data
UNWIND [1, 2, 3, null] AS x
RETURN x
where the values 1, 2, 3, and null will be returned as individual rows to the caller.
LOAD CSV WITH HEADERS FROM 'places.csv' AS line
MERGE (:Place {country: line.country, city: line.city})
Since the place data is uniform, you can use a straightforward LOAD CSV pattern to insert the nodes into the knowledge graph. LOAD CSV is the Cypher command you want to execute. WITH HEADERS tells the command to expect header definitions in the first line of the CSV file. FROM ‘places.csv’ tells the command where to find the CSV data. AS line binds each row in the CSV file to a variable in Cypher called line that can be accessed subsequently in the query.
If there are irregular person nodes and want to avoid the null values
LOAD CSV WITH HEADERS FROM 'people.csv' AS line
MERGE (p:Person {name: line.name})
SET p.age = line.age
SET p.gender = line.gender
SET is used to avoid writing any null properties into the nide which would cause the operation to fail. Finally, you can add the LIVES_IN and FRIEND relationships to link the new nodes into a knowledge graph.
We can load the FRIEND relationships with the property data
LOAD CSV WITH HEADERS FROM "friend_rels.csv" AS line
MATCH (person:Person {name:line.from}), (place:Place {city:line.to})
MERGE (person)-[r:LIVES_IN]->(place)
SET r.since=line.since
It is often recommended to do the updates in batches. This ensures that the database isn’t overwhelmed with large inserts and keeps the other queries on the knowledge graph running smoothly. From Neo4j 4.4, similar functional‐ ity is available directly in Cypher using CALL {…} IN TRANSACTIONS OF … ROWS. Using this method you can change the loading of Person nodes into smaller batches.
LOAD CSV WITH HEADERS FROM 'people.csv' AS line
CALL {
WITH line
MERGE (p:Person {name: line.name})
SET p.age = line.age
SET p.gender = line.gender
} IN TRANSACTIONS OF 1 ROWS
There is one other faster way to import the data which is neo4j-admin Here we first assemble the data into CSV files and place them on a filesystem that the importer can access. The filesystem doesn’t necessarily have to be local it can be network mount. The neo4j-admin import tool is very fast and suitable for very large datasets (containing many billions of records), with approximately a million records per second of sustained throughput.
Integrating Knowledge Graphs with Information Systems
There are several ways the knowledge graphs can be integrated into the data layer. This is abstract layer that connects to access any third party system and allows users to access data transparently. The knowledge graph provides a sophisticated index to curate data across silos irrespective of how the data is physically stored in those silos as relational tables or NoSQL
The knowledge graph provides a curated index across multiple underlying data systems and act as an entry point. The organizing principle discussed earlier can be used to validate data across systems and check for inconsistencies or violations of the semantics of the data.
The most common way to integrate knowledge graph is through driver which is client side middleware that sits underneath the application code and makes network calls to knowledge graph.
There are multiple Neo4j drivers for common programming languages and frameworks. Here is snippet of java Neo4j Driver
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
import org.neo4j.driver.Result;
import org.neo4j.driver.Session;
import static org.neo4j.driver.Values.parameters;
public class JavaDriverExample implements AutoCloseable
{
// Driver instances are quite expensive.
// You typically want just one of these for your whole application lifetime.
private final Driver driver;
public JavaDriverExample(String uri, String user, String password )
{
// 1. Driver objects are expensive
driver = GraphDatabase.driver( uri, AuthTokens.basic( user, password ) );
}
@Override
public void close() {
driver.close();
}
public Result findFriends(final String name)
{
// 2. Sessions are cheap. Use them whenever you need them.
try ( Session session = driver.session() )
{
// 3. Telling the driver whether the query updates the graph (or not)
// helps to make good routing decisions in a cluster.
// Session#writeTransaction is also available.
return session.readTransaction(tx ->
{
Result result = tx.run("MATCH (a:Person)-[:FRIEND]->(b:Person) " +
"WHERE a.name = $name " + // 4. Parameters are good
"RETURN b.name",
parameters("name", name));
return result;
});
}
}
public static void main(String... args ) throws Exception
{
try ( JavaDriverExample example =
new JavaDriverExample( "bolt://localhost:7687",
"neo4j",
"password" ) )
{
example.findFriends( "Rosa" );
}
}
}
- Driver objects are expensive so consider using only one throughout the lifetime
- Session Objects are cheap
- Tell the receiving server whether a query is read-only or read/write to help better have routing decisions
- Parameterize all queries as they are faster than using literal strings across the network.
Neo4j Composite Databases enable you to bring together multiple graph data sources and provide a single unified point of access to all of them. This technique is called federation.
Neo4j has an excellent library of functions and procedures that come with the database. We do not need to use APOC to make calls into SQL database to enrich knowledge graph. The cypher code loads a SQL database driver into Neo4j and then uses it to access a SQL database called northwind. The CALL deals with connecting to the remote database, and returns data from a MongoDB query in a format suitable for further Cypher processing.
If your underlying data is in different nongraph sources, like time-series data, clickstream data, or log data, you’re going to have to use a different approach. The APOC library supports the definition of a catalog of virtual resources.
A virtual resource is an external data source that Neo4j can use to query and retrieve data on demand, presenting it as virtual nodes enriching the data stored in the graph
The library call sits as an intermediary between the end user and the databases they want to use, which include a Neo4j graph, a CSV file, and a relational database. As queries are executed on the graph database, the APOC library retrieves data from the CSV file and relational database and presents it as virtual nodes and relationships to the query engine where they are mixed in with the native graph data from Neo4j.
Cypher is extensible. It allows both user-defined functions and user defined procedures, so you can build functions and procedures to suit your own exacting needs.
GraphQL is the framework for API construction and a run time environment for executing API calls. Using GraphQL to access a knowledge graph stored in a native graph database offers several advantages.
Apache Kafka is a popular enterprise middleware platform, acting as the glue between systems. Integrating knowledge graphs with Kafka is straightforward. Using Kafka Connect Neo4j Connector, your knowledge graph can serve as a source of data, such as change data or as a sink to ingest data from Kafka events into your knowledge graph.
Apache Spark is a (distributed) data processing framework for working with large data sets. Neo4j connector to be installed in the Spark environment and we can perform operations on the underlying graph.
Apache Hop can be chosen because it’s open source and has good connectivity for knowledge graphs hosted in Neo4j. For more sophisticated mappings, you can also specify Cypher queries to run for knowledge graph ingress and egress.
Enriching Knowledge graphs with Data Science
Graph algorithms is needed to execute them over knowledge graph. There are many graph algorithms to choose from. There are 3 broad categories of algorithms.
Statistical — Provides metrics about the graph such as number of nodes and relationships, degree distribution of relationships, types of node lables and so on. These provide context for interpretation of results
Analytical — Surfaces significant patterns or latent knowledge over the whole knowledge graph or significant subcomponents.
Machine Learning — Use the results from the graph algorithms as features to train machine learning models or uses machine learning to evolve the knowledge graph itself.
Within Statistical and analytical methods there are 5 categories that are common to knowledge graph use cases:
Network Propagation — Understands how signals propogate through a knowledge graph requires deep path computations. The results can be used to optimize for containment or adding redundancy to critical paths.
Influence — Influential nodes act as bridges between subgraphs and are ideally positioned to spread information around the network quickly since they are close to all other nodes and the measure of node’s influence is known as centrality.
Community detection — Being able to detect communities in a knowledge graph tells you about related works that you might want to read
Similarity — Similarity algorithms search for known relationships / hierarchies between nodes or common properties on them.
Link Prediction — These algorithms enrich the knowledge graph by computing missing relationships.
Each algorithm behaves differently and will typically give different results for the same input.
Neo4j Graph Data Science is a graph computation framework that is integrated with Neo4j Graph Database and they project data from knowledge graph stored in Neo4j and then compute an analysis using a graph algorithm. Neo4j Graph Data Science offers a broad range of high-performance, parallelized algorithms. You choose an algorithm based on the kind of insight you need and run algorithms with Cypher procedure calls.
4 distinct phases of executing a graph algorithm over the knowledge graph
Read Projected Graph — Choose the parts of the graph that you are interested in processing and create a projection which can be a subgraph
Load Projected Graph — Export the graph projection into a compact, in-memory format ready for parallel processing
Execute Algorithm — Run the algorithm with parameters you choose
Store Results — Write results back into the knowledge graph or compute results that can be sent to downstream systems or the calling user.
A common setup to support knowledge graphs and graph algorithms is to separate your physical servers by role, providing physical isolation for different workloads. Neo4j supports the concept of primary and secondary servers for this purpose. Primary servers are responsible for transaction processing, keeping your knowledge graph clustered for scale and fault tolerance. They also typically serve Cypher queries.
Primaries can also run graph algorithms, but doing so would cause contention between the computational workload of the algorithms and the ongoing database workload. Instead, consider deploying secondary instances for data science. Secondary instances have looser time guarantees about updates compared to primaries since they receive their updates asynchronously rather than transactionally.
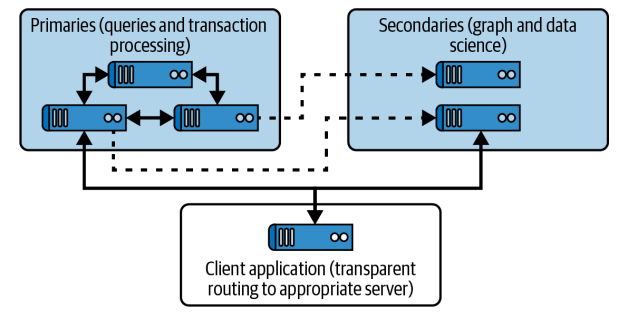
The infrastructure of Neo4j clusters allows you to tag servers with their intended roles so that users of the system send their jobs to the most appropriate physical server for their needs
Graph Native Machine Learning
The choice of ML model is an expert decision, but fueling that ML with knowledge graphs typically makes good sense. There are two ways you might choose to integrate graphs and ML:
- To predict how a knowledge graph will evolve over time, known as in-graph machine learning
- To extract features from the knowledge graph to build a high-quality external predictive model, known as graph feature engineering
In-graph machine learning is a collection of techniques where the knowledge graph can be enriched by computing over itself. The process searches for opportunities to add missing relationships, node labels and even properties.
We can also improve link prediction by moving to an ML pipeline where we need reasonably large set of relevant training data from which features can be extracted by the ML pipeline to train a predictive model.
Graph feature engineering involves identifying and extracting data from a knowledge graph to be integrated into an ML model. Since knowledge graphs have a topology as well as data, this enables you to extract more and typically higher-quality features than would otherwise be possible.
If the scope of the in-graph ML pipelines isn’t sufficient for your needs, you can always fall back on external tools like TensorFlow, PyTorch, and scikit-learn or cloud-hosted systems like Google’s Vertex AI, Amazon SageMaker, and Microsoft’s Azure Machine Learning. The bridge between the two domains is the set of feature vectors extracted from the knowledge graph which is used as input to train and test the externally hosted model. Through experimentation and iteration (either automatically or manually), it may be possible to use the greater depth of these tools and platforms to create better ML models, at the expense of implementation complexity, especially enriching the knowledge graph with the results from those external systems.
Mapping Data with Metadata Knowledge Graphs
A metadata knowledge graph is an enterprise-wide map which records the shape and location of data, the systems which process that data, and its consumers. A metadata map provides a lens over an organization’s entire data ecosystem, allowing you to manage data across the enterprise.
To address metadata challenges, large companies like Airbnb (Dataportal), Lyft (Amundsen), and LinkedIn (DataHub) built metadata hubs backed by knowledge graphs. These hubs capture datasets, tasks, pipelines, and sinks, serving as guidelines for metadata management.
The Key core elements of Metadata Graphs are
- Datasets which are tables, documents, streams and connected to data platforms and it is described with schema fields
- Tasks and Pipelines like ETL which are data jobs chained into flows showing dependencies and data lineage
- Data Sinks which are final consumers of data like BI dashboards or ML training data sets
These metadata knowledge graphs can help enterprises reunify distributed systems logically and makes architectures easier to reason about. They also provide transparency for auditing, regulatory compliance and internal governance. It serve as a foundational layer for advances knowledge graph systems and machine learning
Identity Knowledge Graphs
It is determining whether two records represent same entity in real-world. The issue arises in data integration, master data management and entity resolution tasks. There can be strong identifiers which are unique for example passport number, SSN but there are weak identifiers like address, names and emails that can be missing or duplicate. Knowledge graphs allow combining weak identifiers with graph algorithms to infer identity.
The process of entity resolution includes 3 activities:
- Data Preparation — Making sure that the data meets required quality characteristics. Sometimes uses generating blocking keys to reduce search space.
- Entity Matching — The identity logic is applied where these rules can vary in complexity.
- Curation of persisted record of master entities — Detecting sets of connected nodes in the graph either through SAME_AS or SIMILAR relationships
Graph techniques and algorithms like Weakly Connected Components (WCC) or Node Similarity are used to cluster records into unified golden records which represent the true entity behind fragmented records.
There are use cases like fraud detection, personalization, compliance and customer 360 views
Pattern Detection Knowledge Graphs
A knowledge graph can be mined for patterns that originate from interesting business events. Those patterns give historical insight into the business, but they can also be used to look forward
For Instance, Fraud Detection use case where there is extra cost in damage control and reputation. The traditional rule-based systems with risk scores and manual reviews are slow and inflexible where as graph based approach represent accounts, transactions and entities as nodes/edges and spot patterns such as fraud rings or unusual transaction chains. It also runs queries to distinguish legitimate customers from fraudsters.
We can also think about Skill Matching and Team building based on multiple dimensions where it builds layers like org chart, expertise, project history, social engagement and languages. It also allows to query across layers to assemble well-balanced and effective teams.
Graphs enable low-latency checks and deeper analysis of the problems. It leverages structure, context and algorithms
Dependency Knowledge Graphs
Each individual direct dependency is modeled as a relation‐ ship between nodes that build out into networks of transitive dependencies. These dependency networks form a graph, and many dependency problems can be resolved with graph pattern matching and graph algorithms.
Understanding dependencies is critical for impact analysis, fault tolerance and resilience planning. Relational databases struggle with recursive dependency queries but knowledge graphs naturally capture multi-level dependencies.
Dependencies are not just binary; they often have weights or percentages. and can also have temporal validity
There are two main interpretations of node depending on multiple others
- Additive/Aggregate — Contributions add up like porfolio investments and bonded network links. The impact propagates proportionally to weights
- Redundant/ Protection — Only one of several dependencies is needed where system survives as long as threshold is met.
When a failure occurs, the impact propagates through the dependency graph. The Graph queries can calculate how failures cascade across systems, weighted by dependency strength.
To ensure the correctness, dependency graphs should be validated for and it should form a Directed Acyclic Graph (DAG) and aggregated weights should sum correctly and also the thresholds and redundancy conditions holds true.
Sematic Search and Similarity
Most data exists in unstructured documents and natural language is ambiguous and inconsistent making keyword search unreliable.
Graphs enable semantic search by modeling things not strings. NoSQL database management systems” can retrieve documents about Neo4j, even if the phrase isn’t present, because the graph encodes that “Neo4j → Graph Database → NoSQL. Queries can recursively traverse hierarchies (ontologies, taxonomies) to fetch related concepts
NLP and Named Entity Recognition (NER) are used to extract entities. These are linked to an organizing principle (ontology, taxonomy, concept scheme). This adds structure and relationships, allowing search to be based on meaning rather than keywords. Graphs store similarity metrics (e.g., between articles). Example Cypher query: retrieve the top 5 similar articles for a given one. Helps solve the cold start problem: Without prior user history, recommend trending concepts or use precomputed similarity scores
Some real-world applications include
- Healthcare: Annotating discharge summaries and clinical notes to enable patient-centric search.
- Media: Tagging articles with entities (people, places, events) for personalization and nonlinear content navigation.
- NASA case study: Their Lessons Learned Information System (LLIS) was underutilized due to siloed documents and poor keyword search. By building a knowledge graph of entities, topics, and relationships, they reduced irrelevant results and improved discovery of lessons that could prevent future failures
Semantic search = queries based on meaning and relationships, not just text matches. Similarity = leveraging graph connections and metrics to recommend related content. Knowledge graphs bridge NLP with structured ontologies, making unstructured text actionable.
Talking to Your Knowledge Graph
We can integrate the knowledge graph in multiple ways.
- Natural Language Processing can be used to populate the graphs with entities and facts. It goes beyond document search. Instead of returning documents, the graph directly answers questions like “Who is the CEO of Tesla?”. Moves from entity extraction to fact extraction, where text is parsed into statements stored as nodes/relationships in the graph. Tools like Diffbot can automate fact extraction for building question-answering graphs
- We can use knowledge graph to generate human-readable answers or reports from the graphs. Allows querying the graph in natural language instead of Cypher or other query languages. Uses NLP libraries (like spaCy) to process questions and translate them into structured graph queries. This lowers the barrier for non-technical users
- We can also support NLP tasks with structured lexical or conceptual information. Graphs can generate text-based answers or reports. Specialized graphs (e.g., WordNet) serve as lexical knowledge bases. They power custom entity extractors and semantic similarity metrics (like Path, Leacock-Chodorow, Wu-Palmer). Useful in domain-specific tasks where general-purpose NLP isn’t sufficient.
From Knowledge Graphs to Knowledge Lakes
Knowledge graphs often start small and departmental (e.g., marketing, compliance). Over time, they expand, interlock across departments via ontologies and middleware, and eventually become enterprise-wide foundational assets. At this stage, they underpin other knowledge-intensive systems.
As graphs proliferate, enterprises face challenges managing many of them in parallel.
The solution is a Knowledge Lake:
- An architecture that subsumes many knowledge graphs and even non-graph data.
- Positioned alongside data warehouses and data lakes.
- Stores a curated, graph-based subset of enterprise data for reuse across multiple projects
- Data lakes emphasize volume and throughput: pouring in raw data for later processing.
- Knowledge lakes emphasize meaning: contextualizing data after the fact to make it usable.
- Together, they provide the best of both worlds: scale + semantics
- A knowledge lake can start small (like a single system) and expand over time.
- Needs governance and automation to prevent staleness or fragmentation.
The end goal: a knowledge lake that maps the entire enterprise’s data, ensuring it can be discovered, reused, and curated
We’re not short of data; the challenge is to make sense of it. Knowledge lakes represent a scalable way to understand enterprise data in context. They promise the ability to query and extract value from even the most complex data-intensive systems as easily as from a single database
