
ML Series — Machine Learning based auto scaling approach in Microservice Architecture
Recent advances in Machine Learning have opened up mew possibilities in Microservice journey. In particular, the researchers have been exploring the software architecture on how to optimize the resources used by the applications running on the cloud to reduce the cost. This article refers to the paper published in 2021 — A Holistic Machine Learning based Auto scaling Approach for Microservice Applications
Machine Learning based auto scaling approach for microservice applications
In this article, I will delve into the problem the authors aim to solve, explore their innovative approach in addressing it, and offer my own critical analysis of their solution in pictorial format.
Microservice architecture is the mainstream pattern for developing large scale cloud applications as it allows for scaling application components on demand and independently. By designing auto scalers in an efficient way the usage of the resources in the cloud can be optimized which is very costly. In this paper, they propose a novel predictive autoscaling approach for microservice applications which leverages machine learning models to predict the number of required replicas for each microservice and the effect of scaling a microservice on other microservices under a given load. They propose that this approach can give better performance than HPA(Horizontal Pod Autoscalers) and maintain a desirable performance and quality of service level for the target application.
In this paper, the focus is on Waterfall autoscaling which takes advantage of machine learning techniques to model the behaviour of each microservice under different load intensities and the effect of services on one another. Specifically, it predicts the number of required replicas for each service to handle a given load and impact of scaling a service on other services.
- Used data-driven performance models for describing the behavior of microservices and their mutual impacts in microservice applications.
- Using this model, designed the auto scaler
- Used this autoscaler on Teastore application.
About Autoscalers —
Autoscalers are tools or mechanisms used in cloud computing and container orchestration to dynamically adjust the allocation of resources (like servers, containers, or virtual machines) to meet changing demands. They play a crucial role in maintaining performance, optimizing costs, and ensuring scalability.
There are 2 approaches for its decision making paradigm
- Proactive — Proactive autoscaling relies on predictions of future demand to allocate resources before the need arises. It uses historical data, traffic patterns, or machine learning models to anticipate resource requirements.
- Reactive — Reactive autoscaling responds to real-time changes in workload metrics (e.g., CPU utilization, memory usage) to scale resources after a threshold is breached.
Based on predefined rules, policies, or predictions, they scale resources horizontally or vertically.
- Horizontal Scaling — Adds or removes instances (e.g., virtual machines, containers) based on workload changes.
- Vertical Scaling — Adjusts resources allocated to an instance (e.g., CPU, memory) without changing the number of instances.
- Hybrid Scaling — Involves both horizontal and vertical scaling
Based on these classifications we have classified autoscalers into 5 categories —
- Rule-based methods
- Application profiling methods — measures the application capacity with a variety of configurations and workloads and use this knowledge to determine the suitable scaling plan for a given workload and configuration
- Analytical modelling methods — Queuing models are most common. A network of queues is usually considered to model. Like a hybrid autoscaler for microservice applications based on a Layer queueing network model (LQN) named ATOM. ATOM uses a genetic algorithm in a time-bounded search to find the optimal scaling strategy. But this is computationally expensive and demands a complex monitoring system.
- Search-based optimization method — use a metaheuristic algorithm to search the state space of system configuration for finding optimal scaling decision
- Machine learning based methods — uses machine learning models to predict the application performance and estimate the required resources. There are some researches around the proactive autoscaling where they used regression models based on time series forecasting to predict future workload and provision the resources ahead of time based on prediction for future workload. But the disadvantage being overprovisioning or under provisioning of resources owing to the uncertainty of workload arrivals
Based on these information available, the problem statement that this paper focus is —
Avoiding cascading effect of resources — If the service 1 which calls both service 2 and 3 is auto scaled, then service 2 and 3 are proactively auto scaled in order to avoid bottlenecks or overloading the other services.
To design this, they designed 2 machine learning models
- Predictive Model for CPU Utilization — They used average CPU utilization of the microservice replicas as the performance metric for scaling decisions.

CPU model takes the number of service replicas and the request rate of service as input features and predicts the service’s average CPU utilization under the specific load.
- Predictive Model for Request Rate — This predicts the new request rate of microservice after scaling and changing the number of service replicas.
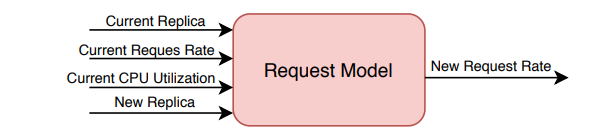
we feed the current replica, request rate and CPU utilitzation an the new number of service replicas as input features and predict the new request rate. The current replica, current CPU utilization, and current request rate describe the state of the service before scaling. The new replica and new request rate reflect the state of the service after scaling. We use the output of the Request Model for a given service to calculate the new downstream rate of that service to other services.
Training Results —
They used Linear Regression, Random Forest and Support Vector Regressor algorithms for the training process and compared them in terms of mean absolute error(MAE) and R² score. Support Vector Regressor and Random Forest provide lower MAE and higher R2 score for CPU Model and Request Model compared to Linear Regression.
Architecture Design
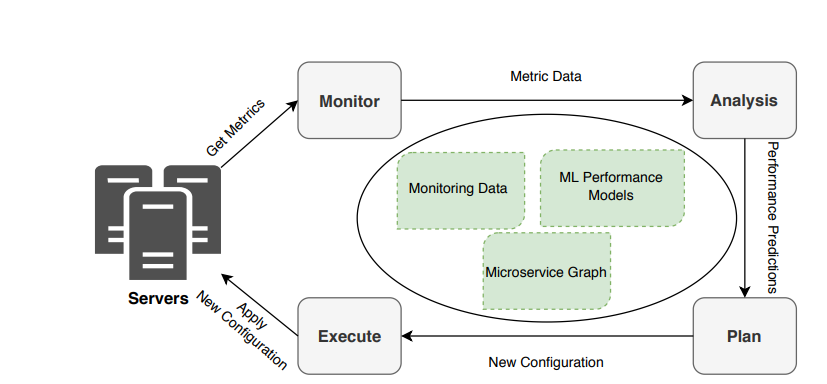
This is the autoscaling algorithm proposed where the request rate and CPU utilization is fed into the system. Based on the threshold, if exceeded it changes the autoscaling configuration and updates the services with new configuration
There are 2 main parameters considered which is Request Rate and Downstream rate and based on the increase or decreases the scale in and scale out is designed.
Tools Used —
- Kubernetes
- Jmeter for load testing
HPA scales a service whenever the service’s average CPU utilization goes above the scaling threshold. However, Waterfall scales a service in two different situations:
— the CPU utilization of the service goes beyond the scaling threshold
— the predicted CPU utilization for the service exceeds the threshold due to scaling of another service
Observations or findings—
They compared the behavior and effectiveness of waterfall autoscaler with HPA —
The overall experiment they found that the ideal way should be as the request rate increases with the CPU utilization and crosses the threshold which is red dotted line, the autoscaling should happen.
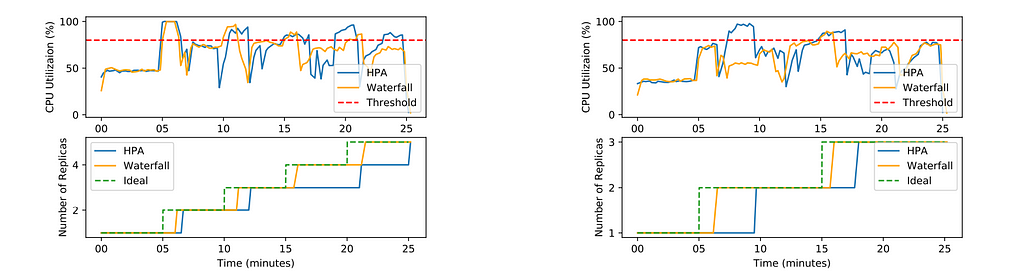
But the waterfall shows better performance than the HPA.
Expanding the Scope: My Recommendations for Improvement
While the paper provides a solid foundation for using machine learning in auto-scaling microservices, there are areas where its approach can be enhanced. Based on real-world complexities and challenges faced in large-scale systems, I propose the following recommendations to improve the Waterfall Autoscaler:
Incorporate Broader Metrics for Scaling Decisions
The paper uses CPU utilization and request rate as primary metrics, which limits its adaptability to real-world scenarios. Consider these metrics:
- Memory Utilization: Microservices handling data-intensive workloads might experience memory bottlenecks before CPU saturation.
- Disk I/O: For services interacting heavily with databases or file systems, scaling might be triggered by high disk activity.
- Network Latency and Bandwidth: Services with significant intercommunication might need scaling based on network congestion or throughput.
- Error Rates and Retries: A spike in error rates might indicate hidden issues like slow database queries, which scaling could address.
- Service-Level Objectives (SLOs): Metrics aligned with user experience, like 99th percentile latency or transaction completion time, could ensure scaling improves QoS.
Advanced Dependency Modeling
The cascading effect discussed in the paper is vital, but the dependency relationships among services can be more complex. Creating a dynamic service dependency graph and using advanced modeling techniques like graph neural networks can better predict the impact of scaling one service on others.
The paper assumes static dependencies among microservices. This can be improved by:
- Dynamic Dependency Mapping: Continuously monitor service interactions to reflect changing call patterns.
- Impact Prediction on Asynchronous Services: Many microservices communicate via asynchronous methods (e.g., message queues). Scaling impacts in such systems are non-linear and harder to predict.
- Categorization of Dependencies: Classify dependencies into critical, optional, or redundant to prioritize scaling efforts.
Advanced Learning Techniques
The models use traditional regression techniques. Consider:
- Time-Series Models: Utilize LSTM or ARIMA for better handling of temporal workload patterns.
- Reinforcement Learning (RL): An RL agent could explore and learn optimal scaling strategies dynamically, balancing cost and performance.
- Graph Neural Networks: Capture interdependencies among services better than linear models.
Addressing Large-Scale Challenges
In environments with hundreds of microservices, challenges such as monitoring overhead, resource contention, and scaling decision latency become significant. Introducing techniques like adaptive monitoring and lightweight prediction models can mitigate these issues
Enhancing the Generalizability of Models
Machine learning models trained on specific workloads might fail to generalize to diverse service types. Periodic retraining and leveraging online learning can ensure the models adapt to evolving workloads.
- User Demand Prediction — Go beyond immediate metrics to incorporate external predictors like seasonal traffic patterns, marketing events, or social media trends, improving proactive scaling accuracy.
- Cost-Aware Scaling —Include financial constraints in scaling. For example, prefer scaling in cheaper regions during non-peak hours.
- Integrating Observability for Better Insights — Observability tools like Jaeger, Prometheus, and OpenTelemetry can be integrated to provide deeper insights into inter-service dependencies and system health, aiding in proactive scaling decisions.
Happy Learning!!
