
Do you know we can make AI agents faster and more cost-effective by adding a sematic cache? In many production grade applications, inference costs and latency affect the ability to scale the application. Traditional input and outputs caches that work when the input text is exactly the same and help in some cases. Suppose if some one ask how can I get money back and other ask how can I get refund, a normal exact match cache sees them as completely different.
Sematic Caching looks at the meaning, it uses embeddings to measure how similar two questions are in the meaning space. If they are semantically similar, then we can reuse the model response to an old answer instead of calling the model again.
What to expect in this article?
In this article, we will build a cache from scratch to learn the how semantic caching works piece by piece and we will create embeddings, compare distances and set a threshold to decide when two queries are semantically similar enough. Then we will implement semantic cache using Redis as open source SDK. This is similar to production deployment as the cache will have features like time to live to keep your cache fresh and small and even separate caches for different users or teams or tenants. Then we will move to performance metrics like hit rate, precision and recall which shows how often the cache helps and how often it is correct. we can visualize them using confusion matrix and how it is changing the similarity threshold will shift the balance between precision and recall. we will look at how effectiveness of cache can actually reduce latency. We use cross encoder for better re-ranking and even small LLM that can confirm whether 2 questions mean the same thing. We will add fuzzy matching to handle simple typos that frequently happen when users ask questions. Finally, we will connect it to AI agent that breaks a big question into smaller parts and checks the cache for each one and only calls the LLM when it needs to. This means every new user or slightly different phrasing benefits from what the system already knows. Over time, as cache warms up, the model calls drop and responses feel just as good but arrive much faster.
Overview of Semantic Caching
Model quality tends to go up with cost per token. That curve is improving but the price and latency tradeoff is still gating factor on real-world deployments. This is the major huddle as popular models for reasoning and solving complex tasks like GPT-5 or Claude are just more expensive and also slower. For many teams, inference, not data plumbing is now the dominant unit cost in AI system.
Organizations are building Retrieval Augmented Generation Systems or RAG. These systems can infuse domain specific knowledge into the prompt of a large language model and make them so they reduce hallucinations by inserting the right information at the right time. Also stay fresh by providing up-to-date information at runtime that the large language model has never seen before. AI agents by nature extract, plan and act and reflect and iterate over multiple, multiple passes. So agents use multiple LLM calls throughout the course of execution. This consumes more tokens, adds additional latency and the prompt lengths also grow over time. And as we can see through this one benchmark

According to real-world benchmarks, the average cost of a complex agent workflow can reach up to $6.8 which is end to end execution of a flow. Customer support agents accelerate mean time to resolution (MTTR) of open customer inquiries.
Let us talk about the classic principle called caching. The idea is not to repeat yourself on redundant information. Users might ask multiple questions of agents and in these cases we can check the cache for queries that have already been answered in the past and avoid invoking the large language model when we don’t have to.

This is great idea but the problem is that a naive exact match caching fails for natural language. In traditional caching, you use exact matches on string data. The words and tokens and characters have to be exactly the same in order to get a cache hit. This yields perfect precision but really poor recall and in most cases very low cache hit rates for natural language. Sematic caching uses the advantage of the meaning of the questions and not it brings with higher recall and higher cache hit rates, the ability to influence performance. This also risk the false positives. This introduces opportunity for the cache to hit on the incorrect thing.
Sematic Cache Working
- Embed user query — this converts the user question into a vector that we can use for semantic search
- Compare Similarity — Compare the user query if it is similar to every entry in our semantic cache.
- Classify — Compare the nearest neighbor vector distance against the cache distance threshold. Cache hit return stored answer instantly and cache miss call RAG system get new answer, respond and write back into cache
- RAG System involves generating some kind of search and then some call to the LLM
- Then we respond to the user.
- Once we have answer, update the cache with that question and answer pair to make sure it is reusable in future.
The vector search is the backbone of semantic caching. Vectors are list of numbers and these numbers represent data and encode meaning and semantics. There are many example applications of vector search in the wild including content discovery, search, recommendation systems, or even fraud and anomaly detection.
Semantic Caching in production introduces a new kind of challenges.It is more than just a vector search.
- Cache Effectiveness — In particular, accuracy which measures are we serving the correct results from the cache when we get a hit? Performance — are we making sure that we actually hit the cache often enough to get value from it? And can we actually serve the cache at scale without impacting round trip latency?
- Updatability — Can we refresh, invalidate or warn the semantic cache as data evolves over time?
- Observability — Can we observe and measure cache hit rate, latency, cost savings and cache quality?
In this article, let us focus on 4 different metrics to measure the effectiveness of the cache.
- Cache Hit Rate — frequency of times that we hit the cache given a distance threshold. Primarily influences our cost savings that we get from adding a semantic cache.
- Precision — Quality of hits ( how many hits are correct). Ensures reliability of cached results
- Recall — Coverage ( how many possible correct results are captured) Ensures important queries are not missed
- F1 Score — Balance between precision and recall. Provides a single measure of overall cache effectiveness
There are different ways to improve the cache accuracy and performance.
Precision and Recall —
- Distance Threshold Tuning — Adjust semantic decision boundary to balance recall/precision and reduce false positives
- Cross Encoder Reranker — Re-rank retrieved results with a higher- fidelity model for improved relevance.
- LLM Reranker/ Validator — Use an LLM to validate or refine semantic search outputs.
Efficiency and Resource use —
- Fuzzy matching — Handle exact matches and typos before invoking cache embeddings, saving compute
Context and Filters —
- Temporal Context Detection — Identify time sensitive queries to avoid stale or irrelevant cache hits
- Code detection — Filter out domain-specific content that should bypass semantic caching
Building First Sematic Cache
Let us load a sample FAQ dataset. For this I’m using a customized code to extract the csv file in the location file named “faq_data_container.py”
Entire code here -https://github.com/shilpathota/SemanticCaching/blob/main/E2E_UseCase.ipynb —
The notebook begins with a simple customer support FAQ dataset containing 8 frequently asked questions and 80 test queries. This realistic scenario mirrors what customer service chatbots encounter daily — users asking the same questions in different ways.
When you embed “How do I get a refund?” and “I want my money back,” the resulting vectors are positioned close together in high-dimensional space because they share similar meaning, even though the exact words differ.
The core algorithm uses cosine distance to measure similarity between question embeddings. Lower distances indicate higher similarity. The semantic search function:
- Embeds the incoming query
- Calculates distances to all cached questions
- Returns the closest match
The check_cache() function implements a distance threshold strategy (default: 0.3). If a query's similarity to a cached question falls below this threshold, it's considered a cache hit. This approach shows:
- ✅ Hit: “Is it possible to get a refund?” (distance: 0.262) → Returns cached answer
- ✅ Hit: “I want my money back” (distance would be calculated)
- ❌ Miss: “What are your business hours?” → No similar cached entry exists
The notebook demonstrates how caches grow organically. The add_to_cache() function shows how to:
- Append new Q&A pairs to the DataFrame
- Generate embeddings for new questions
- Extend the embeddings matrix
After adding three new entries (business hours, mobile app, payment methods), the cache grows from 8 to 11 entries. Subsequent queries like “What time do you open?” now hit the cache with high confidence (distance: 0.289).
Redis Stack extends Redis with the RediSearch module, enabling:
- High-performance vector similarity search
- Automatic index management
- TTL policies for cache freshness
- Distributed caching capabilities
A critical optimization is introduced: langcache-embed-v1, a specialized embedding model designed specifically for caching scenarios. This model is hosted on HuggingFace and optimized to:
- Generate compact yet meaningful embeddings
- Balance similarity detection with cache efficiency
- Reduce false positives in cache hits
The model is wrapped with an EmbeddingsCache that stores embedding computations in Redis (with a 3600-second TTL), avoiding redundant embedding calculations for repeated queries.
The SemanticCache from RedisVL provides a production-ready implementation:
cache = SemanticCache(
name="faq-cache",
vectorizer=langcache_embed,
redis_client=r,
distance_threshold=0.3
)
End-to-end LLM example with caching
Use LangChain’s ChatOllama (or a compatible LLM) to answer FAQ questions.
Wrap LLM calls so that:
- First check semantic cache.
- Call LLM only on cache miss.
- Measure latency with PerfEval from cache.evals.
Measuring Cache Effectiveness
This is done in the notebook — https://github.com/shilpathota/SemanticCaching/blob/main/Measuring_Cache_Effectiveness.ipynb
- cache_wrapper.check_many(test_queries) returns structured results (hit/miss, distance, matched Q&A).
- CacheEvaluator compares these results against ground-truth labels
- Use PerfEval to time: pure cache hits, full LLM calls
Plot latency comparison and compute overall speedup.

- Use LLMEvaluator.construct_with_ollama() to compare Query and cached response vs. Ground-truth answer (or full retrieval match).
- Generate similarity scores and evaluate how often the cache returns answers that an LLM considers “good enough”.
Enhancing Cache Effectiveness
https://github.com/shilpathota/SemanticCaching/blob/main/Enhancing_Cache_Effectiveness.ipynb
Improve precision/recall and robustness of the cache using several techniques:
Threshold sweep
- Systematically vary the semantic distance threshold.
- Re-run CacheEvaluator and plot F1, precision, and recall vs. threshold to choose a good operating point.
Cross-Encoder reranking
- Use a cross-encoder (e.g. from sentence-transformers / transformers) for fine-grained reranking
- Compare basic embedding similarity vs cross-encoder scores on sample sentences
LLM-enhanced evaluation
Re-use CacheEvaluator.from_full_retrieval(...) to check how well the cache approximates a full nearest-neighbors retrieval when combined with reranking
Fuzzy matching
- Generate “fuzzified” versions of user queries using string perturbations (fuzzify_string, jaro-winkler, fuzzywuzzy).
- Use FuzzyCache to recover the intended FAQ question from noisy input.
- Evaluate fuzzy retrieval accuracy with CacheEvaluator
Fast AI Agents with a Semantic Cache
https://github.com/shilpathota/SemanticCaching/blob/main/FastAIAgents_SemanticCache.ipynb
Combine everything into a LangGraph-based AI agent that uses a semantic cache + RAG pipeline and analyze its behavior across realistic scenarios.
Construct a LangGraph agent-
- A WorkflowState dataclass (state for the graph).
- initialize_agent(cache, kb_index, embeddings) to register tools / graph nodes.
- Node functions: decomposition, search, answer synthesis, cache check/store, quality evaluation, etc.
- Three multi-paragraph user scenarios (evaluation, implementation planning, pre-purchase review).
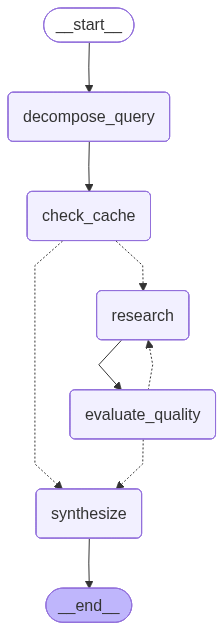
For each scenario:
- Run the agent workflow.
- Collect structured results (e.g. number of cache hits, LLM calls, latencies).
- Use analyze_agent_results from agent.py for performance summary.
From all these learnings built a Deep Research Assistance using Semantic Caching that remember or cache the questions and use it for my next question

The entire code executed is kept in the repository — https://github.com/shilpathota/SemanticCaching
References:
- Redis Vector Search Docs: https://redis.io/docs/latest/develop/ai/
- RedisVL Library: https://docs.redisvl.com/
- Semantic Caching Guide: https://redis.io/blog/what-is-semantic-caching
- https://learn.deeplearning.ai/courses/semantic-caching-for-ai-agents/
