
Distributed Architecture — The key attributes which decides the performance of system design
Designing and operating distributed systems can be challenging due to several factors, including the need for consistency, availability, partition tolerance and low latency. Other attributes such as scalability, durability, reliability and fault tolerance are critical requirements for any business application catering to a large and diverse demography. A good understanding of these attributes are crucial to designing large and complex systems that address business needs.
Suppose we have a system let’s say hotel room booking application.
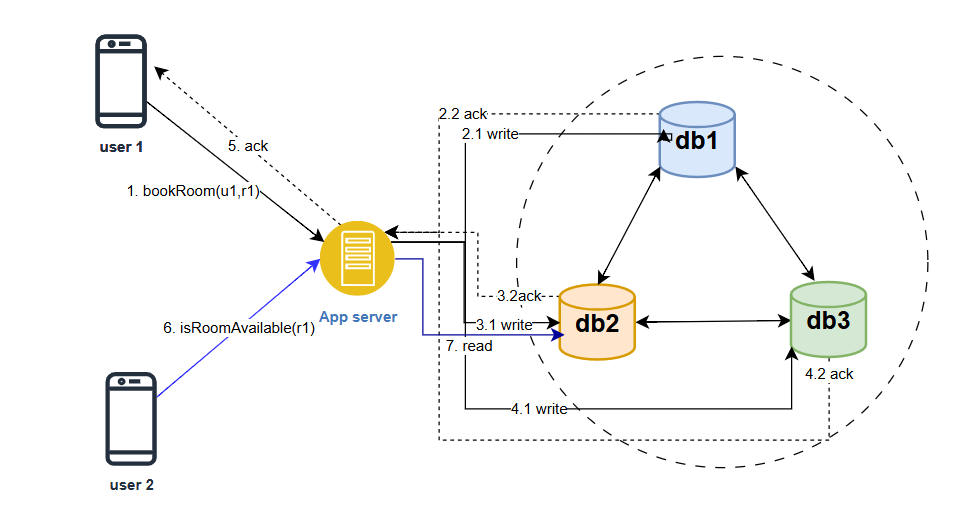
As shown in the figure, a user (u1) is booking a room (r1) in a hotel and another user is trying to see the availability of the same room (r1) in the hotel. Let’s say we have 3 replicas of the reservations database (db1, db2 and db3). There can be two ways the writes get replicated to the other replicas. The app server itself writes to all replicas or the database has the replication support and the writes get replicated without explicit writes by the app server
Write flow
User (u1) books a room (r1). The device/client makes an API call to book a room (u1,r1) to the app server. The server writes to one, a few or all of the replicas.
We have 3 options for write —
- Serial Sync Writes — server writes to each db and gets ack and finally acknowledge the client. Response latency back to user is high.
- Serial Async Writes — Server writes to one db and get ack and then responds to client. The other db are Asynchronously updated. Latency is low
- Parallel Async writes — Server fires 3 updates simultaneously, but does not wait for all the acks, get one ack and respond to client. Latency is low but thread resource usage is high
- Write to messaging service such as kafka and return an ack to the client. Latency is lowest.
Read Flow
User (u2) checks the availability of room (r1). The device/client makes an API call in RoomAvailable(r1) to the app server. The server reads from one, a few or all of the replicas.
Read options are —
- Read from only one replica
- Read from a quorum number of replicas
- Read from all replicas and then return to the client
Consistency
Consistency in distributed system design is the idea that all nodes in a distributed system should agree on the same state or view of the data, even though the data may be replicated and distributed across multiple nodes. In other words, consistency ensures that all nodes store the same data and return updates to the data in the same order on being queried for the same updates to the data in the same order.
There are primarily two types of consistency models that can be used in distributed systems:
- Strong Consistency —
It refers to a property that ensures all nodes in the system observe the same order of updates to shared data. It guarantees that when a write operation is performed, any subsequent read operation will always return the most recent value. Strong consistency enforces strict synchronization and order of operations.
To achieve strong consistency, distributed systems employ mechanisms such as distributed transactions, distributed locking or consensus protocols such as Raft or Paxos algorithms. These mechanisms coordinate the execution of operations across multiple nodes, ensuring that all nodes agree on the order of updates and maintain a consistent state.
However, achieving strong consistency often comes at the cost of increased latency and reduced availability as the system may need to wait for synchronization or consensus before executing operations.
- Eventual Consistency —
It is the consistency model that allows for temporary inconsistencies in the system but guarantees that eventually all replicas or nodes will converge to a consistent state. It allows the updates that are made to the system to propagate asynchronously across different nodes, and eventually all replicas will agree on the same value.
This relaxes the synchronization requirements and accepts that there may be a period during which different nodes have different views of the system’s state. This temporary inconsistency is typically due to factors such as network delays, message propagation or replica synchronization
Eventual consistency is often achieved through techniques such as conflict resolution, replication and gossip protocols. When conflict occurs, such as concurrent updates to the same data on different nodes, the system applies conflict resolution strategies to reconcile the differences and converge towards a consistent state. Replication allows updates to be propagated to multiple replicas asynchronously, while gossip protocols disseminate updates across the system gradually.
It offers benefits such as increased availability and scalability and faster response times to the client application. It allows different nodes to continue operating and serving requests, even in presence of network partitions or temporary failures. It also provides the opportunity to distribute the workload across different replicas, improving system performance.
But how do we decide if we want eventual consistency or strong consistency in our hotel booking example. Sometimes, we may want eventual consistency as a trade-off to have higher availability.
Availability
It is the ability of a distributed system to provide access to its services or resources to its users even in the presence of failures. An available system is always ready to respond to requests and provide its services to users, regardless of any faults or failures that may occur in the system.
Achieving high availability in distributed systems can be challenging because distributed systems are composed of multiple components, each of which may be subject to failures such as crashes, network failures or communication failures.
To ensure availability, distributed systems employ various techniques and strategies —
- Redundancy — Having redundant components or resources enables the system to continue functioning, even if some components fail. It can be software redundancy and hardware redundancy
- Replication — When there is redundancy in the system, we need to replicate the data across these multiple redundant nodes. Even if one or more nodes fail, others can take over and continue to provide the required functionality. Replication can be done through techniques such as active passive replication, where one node serves as the primary while others act as backups, or active-active replication where multiple nodes serve requests simultaneously
- Load Balancing — Distributing the workload evenly across multiple nodes helps prevent the overloading of individual nodes and ensures that resources are efficiently utilized. Load balancing mechanisms route incoming requests to available nodes, optimizing resource utilization and avoiding CPU, memory or I/O bottlenecks that may arise if all requests are served by a small subset of nodes.
- Fault Detection and recovery — Distributed systems employ mechanisms to detect failures or faults in nodes or components. Techniques such as heart beating, monitoring or health checks are used to identify failed nodes, and recovery mechanisms are implemented to restore or replace failed components.
- Failover and failback — Failover mechanisms automatically redirect requests from a failed node or component to a backup or alternative node. Failback mechanisms restore the failed node or component once it becomes available again.
By implementing these techniques, distributed systems can provide high availability, reducing the impact of failures or disruptions and ensure continuous access to services or resources. However, achieving high availability often involves trade-offs, such as increased complexity, resource overhead or potential inconsistencies or performance compromises, which need to be carefully considered based on the specific requirements of the system
Partition Tolerance
Network Partition in distributed systems refers to a situation where a network failure or issues causes a subset of nodes or components to become disconnected or isolated from the rest of the system, forming separate groups or partitions. In other words, the network partition divides the distributed system into multiple disjoint segments that cannot communicate with each other.
Hence, the existence of network partitions poses challenges for distributed systems because it disrupts the communication and coordination between nodes. Nodes within the same partition can continue to interact and operate normally, but they are unable to reach nodes in other partitions. This can lead to inconsistencies, conflicts and challenges in maintaining system properties such as consistency, availability and fault tolerance.
Partition Tolerance is a property of distributed system that refers to the system’s ability to continue functioning despite network failures or network partitions.
In a distributed system that is designed with network partition tolerance, the system can continue to operate despite these network failures. Nodes that are isolated due to a network partition can still function independently and serve their clients, while the rest of the system continues to operate as usual.
Partition tolerance holds immense significance in distributed systems, particularly in scenarios where high availability is crucial, such as cloud computing, distributed databases and large-scale distributed applications.
Latency
Latency is the time delay between the initiation of a request and the response to that request in a distributed system design. It is the time it takes for data to travel from one point to another in a distributed system
Latency is an important metric in distributed system design because it can affect the performance of the system and the user experience. A system with low latency will be able to respond to requests quickly, provides a better user experience, while a system with high latency may experience delays and be perceived as slow or unresponsive.
Latency can be influenced by a variety of factors including the distance between nodes in the system, network congestion, processing time at each node and the size and complexity of the data being transmitted
Optimization techniques includes —
- Network Optimization — Optimizing network infrastructure, such as using high-speed connections, reducing network hops and minimizing network congestion can help reduce latency.
- Caching — Implementing caching mechanisms at various levels, such as in-memory caching or content delivery networks (CDNs) can improve response times by serving frequently accessed data or content closer to the user
- Data Localization — Locating data or services closer to the users or consumers can help reduce latency. This can be achieved through data replication, edge computing or utilizing content distribution strategies.
- Asynchronous Communication — Using asynchronous communication patterns such as message queues or event driven architectures can decouple components and reduce the impact of latency by allowing parallel processing or non-blocking interactions
- Performance tuning — Optimizing system configurations, database queries, algorithms and code execution can help improve overall system performance and reduce latency
Distributed systems often operate in environments with inherent network delays, and achieve extremely low latency may come at the cost of other system properties such as consistency or fault tolerance.
Durability
Durability in distributed system design is the ability of the system to ensure that data stored in the system is not lost due to failures or errors. It is an important property of distributed systems because the system may be composed of multiple nodes, which may fail or experience errors, potentially leading to data loss or corruption
To achieve durability, a distributed system may use techniques such as replication and backup. Data can be replicated across multiple nodes in the system so that if one node fails the data can still be retrieved from another node. Additionally, backup systems may be used to store copies of data in case of a catastrophic failure or disaster.
Durability is particularly important in systems that store critical data, such as financial or medical records, as well as in systems that provide continuous service. By ensuring durability, we can ensure that the system is reliable and that data is always available to users.
Reliability
Reliability in distributed systems means that the system can consistently provide its intended functionality despite the occurrence of various failures and errors such as hardware failures, network issues, software bugs and human errors. A reliable distributed system ensures that data and services are always available, accessible and delivered promptly, even in the face of these challenges
This is the crucial aspect of distributed systems which are composed of multiple interconnected nodes or components working together to achieve a common goal. Achieving reliability in distributed systems requires the implementation of various techniques, such as redundancy, fault tolerance, replication, load balancing and error handling. These techniques help prevent, detect and recover from failures ensuring that the system remains operational and consistent in its behavior.
Fault Tolerance
Fault Tolerance in distributed systems means that the system continues functioning correctly in the presence of component failures or network problems. It involves designing an implementing a system that can detect and recover from faults automatically, without any human intervention.
To achieve fault tolerance, distributed systems employ various techniques, such as redundancy, replication and error detection and recovery mechanisms. Redundancy involves duplicating system components or data to ensure that if one fails, another can take its place without disrupting the overall system. Replication involves creating multiple copies of data or services in different locations so that if one location fails, others can still provide the required service.
Error detection and recovery mechanisms involves constantly monitoring the system for errors or failures and taking appropriate actions to restore its normal functioning. For example, if a node fails to respond, the system may try to communicate with another node or switch to a backup component to ensure uninterrupted service.
Fault tolerance ensures that distributed systems can continue to provide their services even in the presence of failures or errors, increasing their reliability and availability.
Scalability
Scalability in distributed systems refers to the ability of a syste to handle an increasing workload as the number of users or size of data grows, without sacrificing performance or reliability. It involves designing and implementing a system that can efficiently and effectively handle larger amounts of work, either by adding more resources or by optimizing existing resources.
There are 2 types of scaling —
- Vertical Scaling
- Horizontal Scaling
Vertical Scaling
Vertical Scaling also known as scaling up, involves increasing the capacity of an individual nodes/instance or resource within the node. It typically involves upgrading hardware components, such as increasing the CPU power, adding more memory, or expanding storage capacity. Vertical Scaling focuses on improving the performance of a single node to handle increased workloads or demands
Advantages —
- Simplicity
- Cost — effectiveness for smaller workloads
Limitations —
- Hardware limitations
- Single point of failure
Horizontal Scaling
Horizontal Scaling also known as scaling out involves adding more nodes or instances to the distributed system to handle increased workloads or demands. It focuses on distributing the workload across multiple nodes, allowing for parallel processing and improved system capacity
Advantages —
- Increases capacity and performance
- Fault Tolerance
Limitations —
- Distributed Coordination
- Data Consistency
Vertical and horizontal scaling are not mutually exclusive and they can be combined to achieve the desired scalability and performance goals for a distributed system. To ensure scalability, distributed systems must be designed with a modular and loosely coupled architecture, which allows for easy addition or removal of components as needed.
Happy Learning!!
