
Evo-Memory is a new benchmark and framework released by DeepMind that evaluates whether AI agents can continually learn and improve from past experience — not just process isolated prompts. Alongside Evo-Memory, DeepMind introduced ReMem, a memory-evolving agent pipeline that adds a Think → Act → Memory Refine loop, allowing agents to become better over time. This article explains what Evo-Memory is, why it matters, how ReMem works, how it differs from RAG or long-context models, and why it may be the foundation of future agent intelligence.
Limitations of Today’s agents
Currently the agents do not truly learn from their experience. They depend on the memory saved. They read the history of conversations and reply based on the stored memory. They do not actually learn from the mistakes or learn overtime
Can an AI agent improve over time by reusing and refining its own past experiences?
Most benchmarks evaluate LLMs on independent tasks — AIME math questions, GPQA reasoning, MATH, ToolBench, Agent tasks, etc.
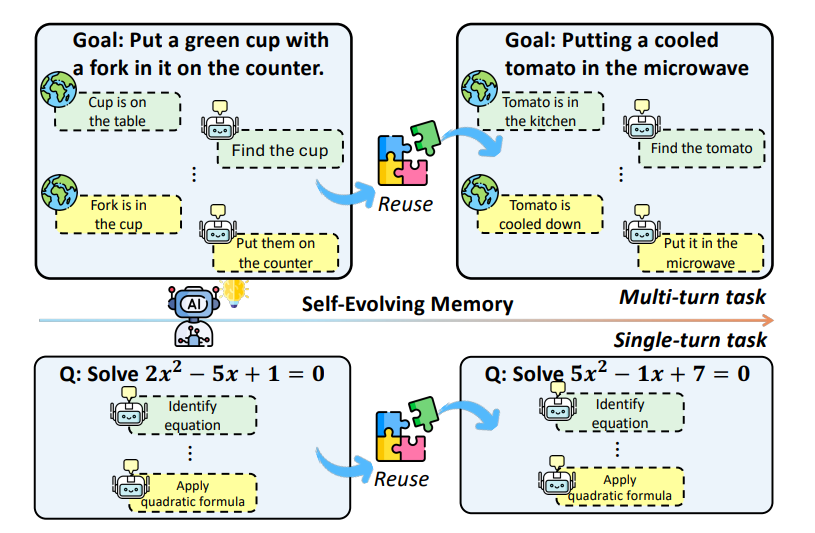
Evo-Memory transforms these into streams of tasks, where:
- earlier tasks teach useful strategies
- agents must store experiences
- agents must retrieve relevant past cases
- agents should refine their memory to get better as they move forward
The agent must teach itself by organizing and evolving its memory.
- LLMs today rely on training-time learning only. Evo-Memory pushes the frontier into test-time lifelong learning.
- Real-world tasks (coding, research, business automation, robotics) require multi-step improvement over time
- Humans do not remember everything — we organize, summarize, prioritize, and refine memory.
- DeepMind reports that agents using memory evolution frameworks outperform non-memory agents on: accuracy, efficiency, number of reasoning steps, ability to solve harder tasks later in the stream
This is the closest step yet toward adaptive, continuously improving AI agents.
The ReMem Framework: Action → Think → Memory Refine
Alongside Evo-Memory, DeepMind introduced ReMem — a unified framework for memory-augmented agents.
ReMem models an agent as a 4-component system: F → Base Model (LLM), R → Retrieval module, U → Memory Update Module and C → Context Constructor
These components allow the agent to: Think, Act, Refine its memory after every step.
THINK → Internal Reasoning, Planning, decomposing the problem
ACT → Take Action by using tools , compute, answer or interact
MEMORY REFINE → Stores new experience, Merges it with older experience, removes noise, creates generalized strategies and reorganizes memory for efficiency
Instead of accumulating raw logs, the agent develops skills, patterns, and lessons over time.
Evo-Memory converts common benchmarks into task streams:
- Sequential math problems
- Sequential reasoning tasks
- Sequential tool-use tasks
- Sequential question-answering tasks
The agent is evaluated not by isolated accuracy but by:
- Does it perform better later in the stream?
- Does it reuse previous experiences?
- Can it refine its memory to solve harder tasks?
This is the first benchmark designed for agent evolution, not static evaluation.
- Evo-Memory agents behave less like chatbots and more like autonomous researchers.
- Agents can recall successful tool sequences and reuse them.
- Memory evolution is required for true personalization.
- Human-level intelligence depends heavily on learning from experience.
Evo-Memory provides the first systematic benchmark for that capability.
Future Research
Evo-Memory raises important research challenges:
- How big should the memory be?
- How do we prevent memory collapse or noise accumulation?
- How should agents decide what to forget?
- How do we avoid catastrophic overfitting to recent tasks?
- How do we keep memory evolution fast and efficient?
These open questions define the next frontier of agent research.
Evo-Memory evaluates whether an AI agent can become smarter with experience, and ReMem provides the mechanism — Think, Act, Refine — for memory that evolves, generalizes, and improves over time.
References
- https://arxiv.org/abs/2511.20857 — Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
